面向非完备数据集的深度学习
Outlines
一个好的数据集应该有以下特征:Accessible、Large-scaled、Balanced、Clean
有以下四个方向:
- 联邦学习:数据分散在各个本地无法直接获取
- 长尾学习:数据不平衡
- 噪声标签学习:标签不准确
- 连续学习:每次只能获取一部分数据
Long-tail Learning
传统的主要处理方法是:
- re-sampling:数据少就多采样几次
- re-weighting:分错一个小类和大类样本loss惩罚力度不一
Re-weighting
最简单的方法是在loss前根据样本的数量加一个权重,$n$ 是样本总数
$$
L_{ce}=-log(p_y)\
L_{ef}=-\frac{n}{n_y}log(p_y)
$$
!但是数量上的差异并不能直接反应模型是否能学好
Class-balanced loss
表示样本的数量增加,但是边际效益是递减的,头部类样本达到一定程度对模型训练是无效,单纯的按样本数量来加权可能会侵害头部分类准确率,需要计算实际有效的样本数
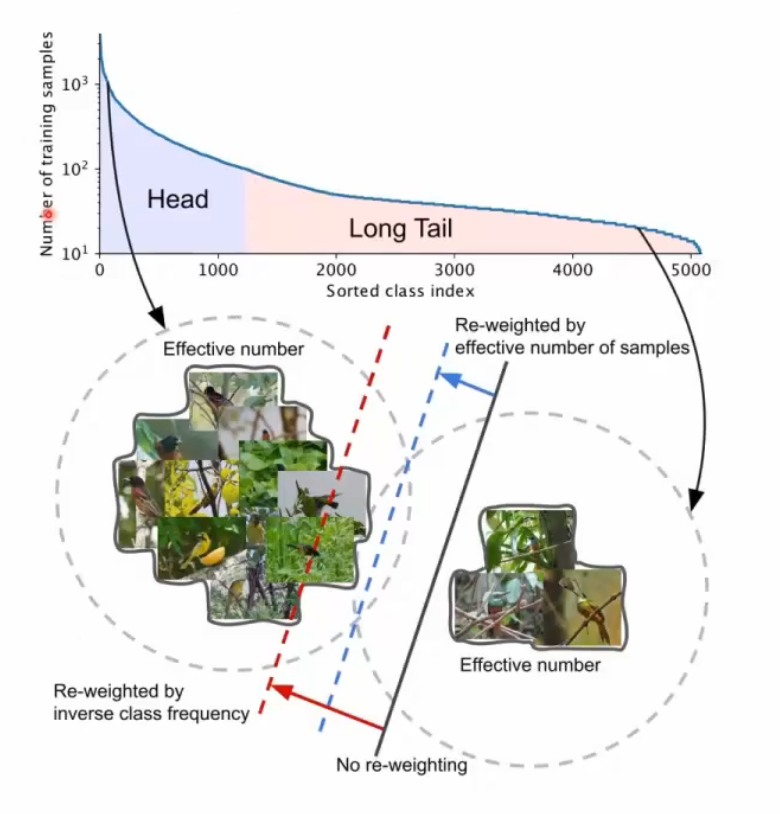
!长尾学习的代价:提升尾部类的时候一般会侵害头部类的准确率
$$
L_{cb}=-\frac{1-\beta}{1-\beta^{n_y}}log(p_y)
$$
LDAM
基于large margin,对每个logit $z_j$都减去一个和样本相关的值,让少数类更确信,p16
$$
L_{ldam}=-log(\frac{exp(z_y-\Delta_y)}{\sum_jexp(z_j-\Delta_j)})\
\Delta_j=\frac{C}{n_j^{1/4}}, j=1,…,k
$$
Augmentation
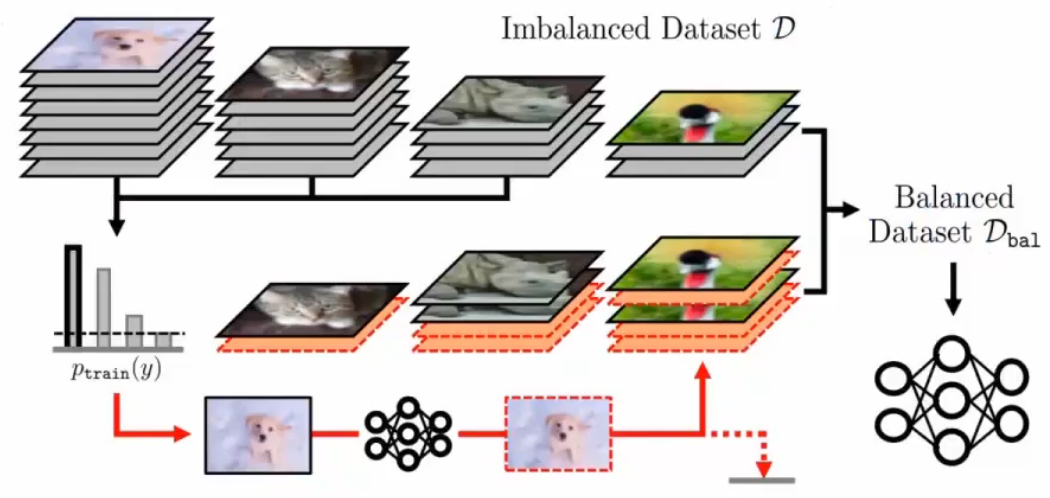
重采样会过拟合严重,单纯的复制样本不行
M2m
Idea: 模型在头部类学习很好,那可以通过模型生成头部类通过学习再变成尾部类来帮助模型学习
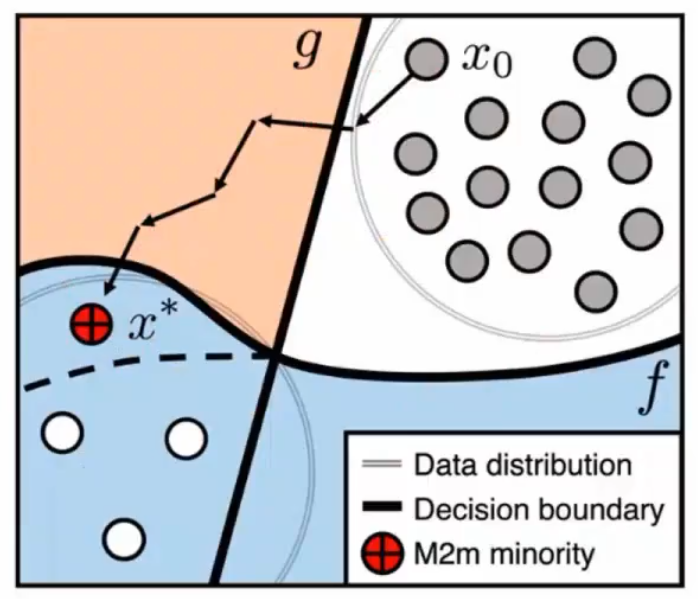
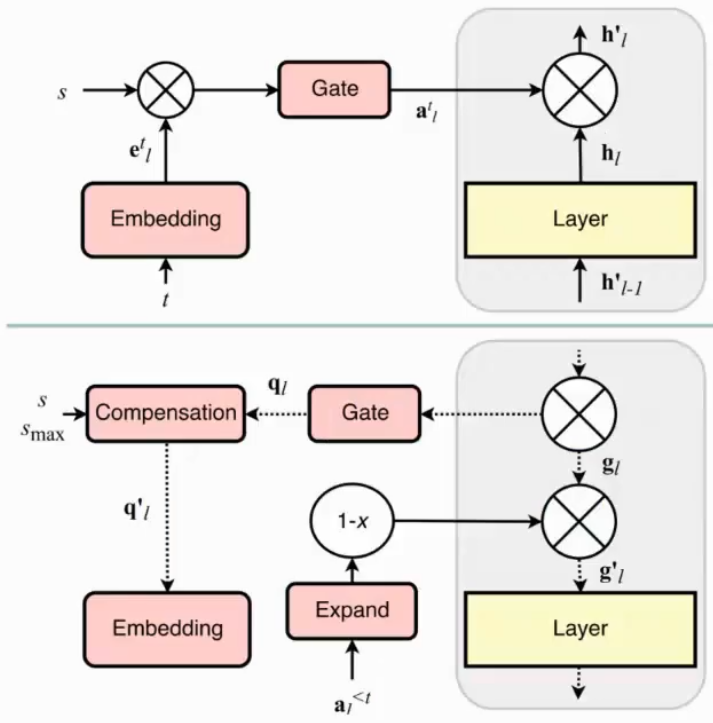
涉及两个模型,两段式,先学差模型然后再不断学好模型
- $g$:原始长尾数据上学习的模型
- $f$:加上了新数据得到的模型
优化目标,要求新生成的样本 $x^$ 尽量被 $g$ 分到尾部类$k$上,而不是被 $f$ 分到原始的类 $k_0$上:
$$
x^=\text{argmin}{x:=x_0+\delta}L(g;x,k)+\lambda f{k_0}(x)
$$
Feature Space Augmentation
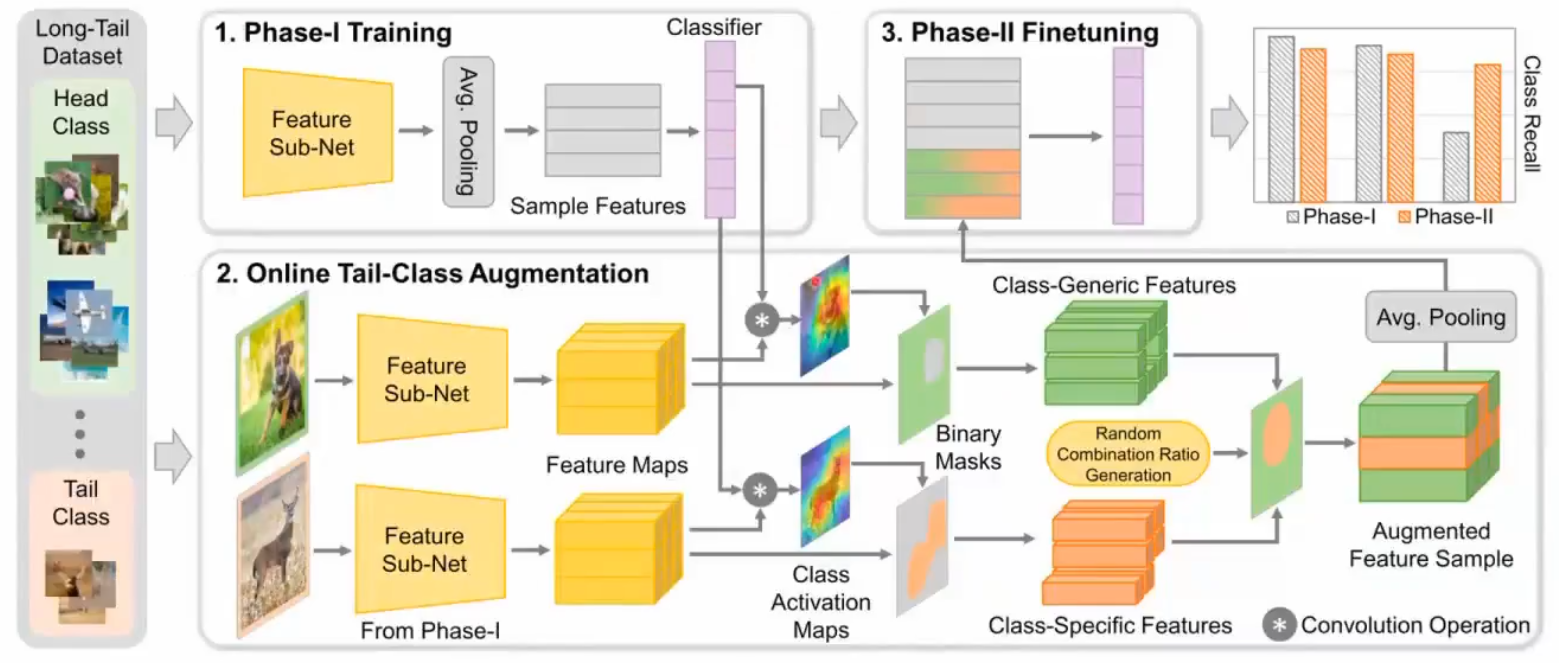
在特征空间进行增广,比如把尾部类的一部分和头部类的一部分进行融合
Decoupling
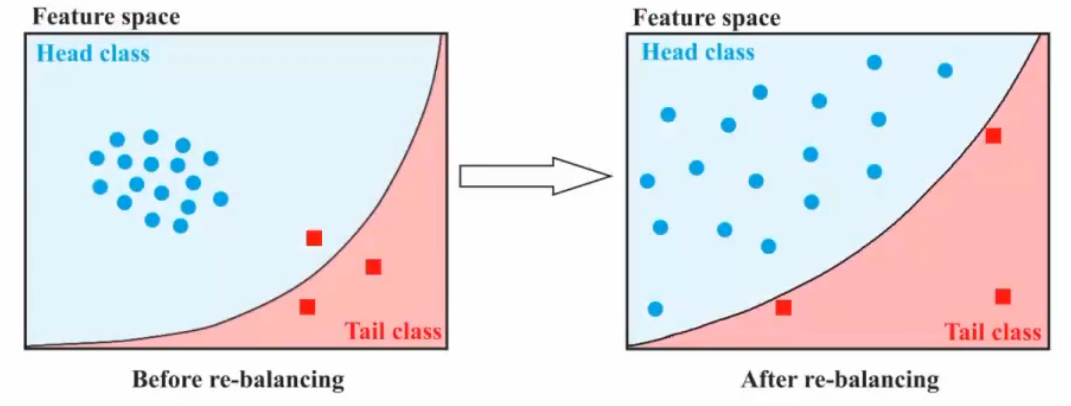
传统的机器学习在不平衡数据上学习时,特征是给好的,所以最重要的是分类准确
但是深度学习领域获得好的表征是最重要的,分类器反而是第二重要的
Question:re-balance的方法是不是一定对特征学习有效呢,会不会加上re-balance之后的确可以分开了,但是类似于一种过拟合,最终把特征空间给打乱了,治标不治本
针对这个问题,分了两个阶段:
- 直接训练整个模型
- 冻住特征提取器,训练分类器
每个阶段可以选择三种策略:1. CE 交叉熵;2. RW: re-weighting;3. RS: re-sampling
得到9种组合:
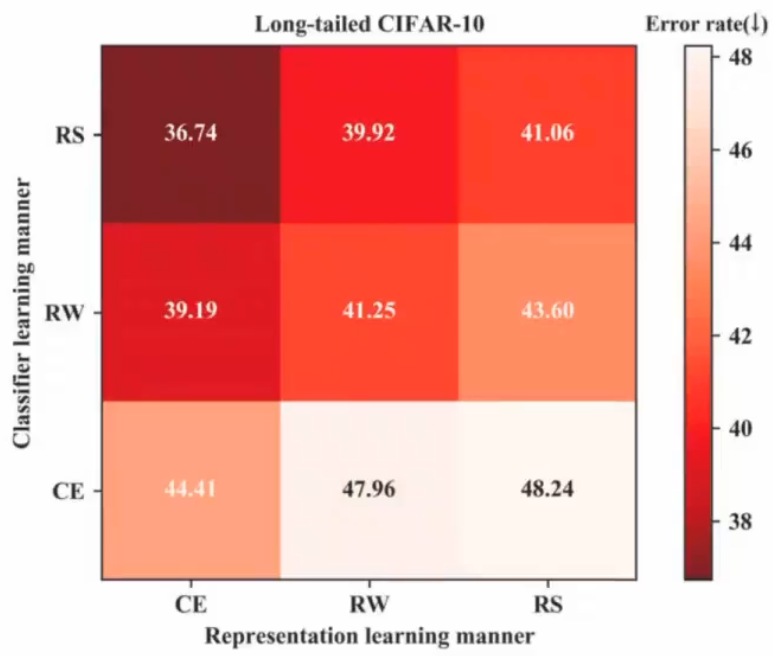
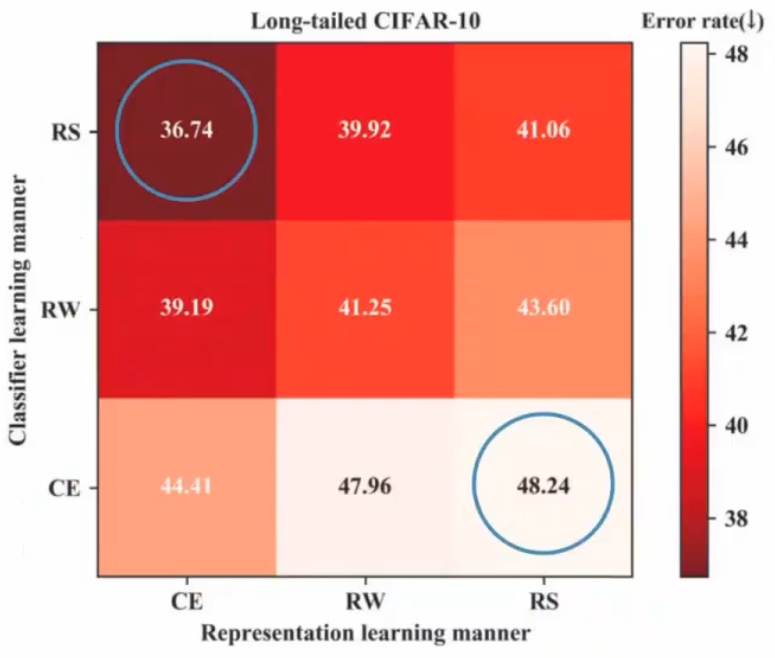
效果最好的是训练特征CE+第二阶段使用RS,最差的是RS+CE,这就是decoupling
最终做法是:
- 第一阶段用CE做特征提取器
- 第二阶段使用Classifier Re-training, Nearest Class Mean classifier, $\tau$-normalized classifier、Learnable weight scaling等一些复杂
BBN
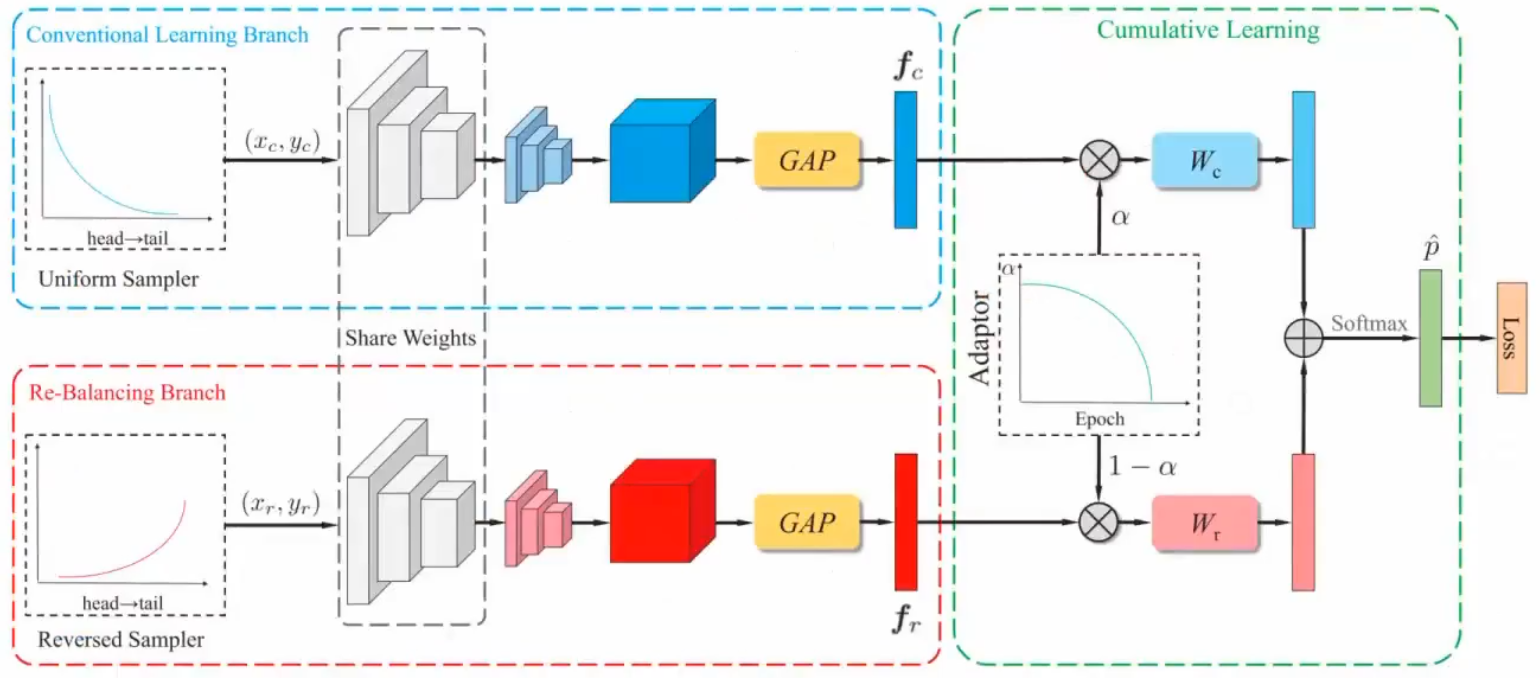
通过一个系数来控制学习偏向哪个阶段,刚开始用正常数据,然后用反比例来训练
Ensemble Learning
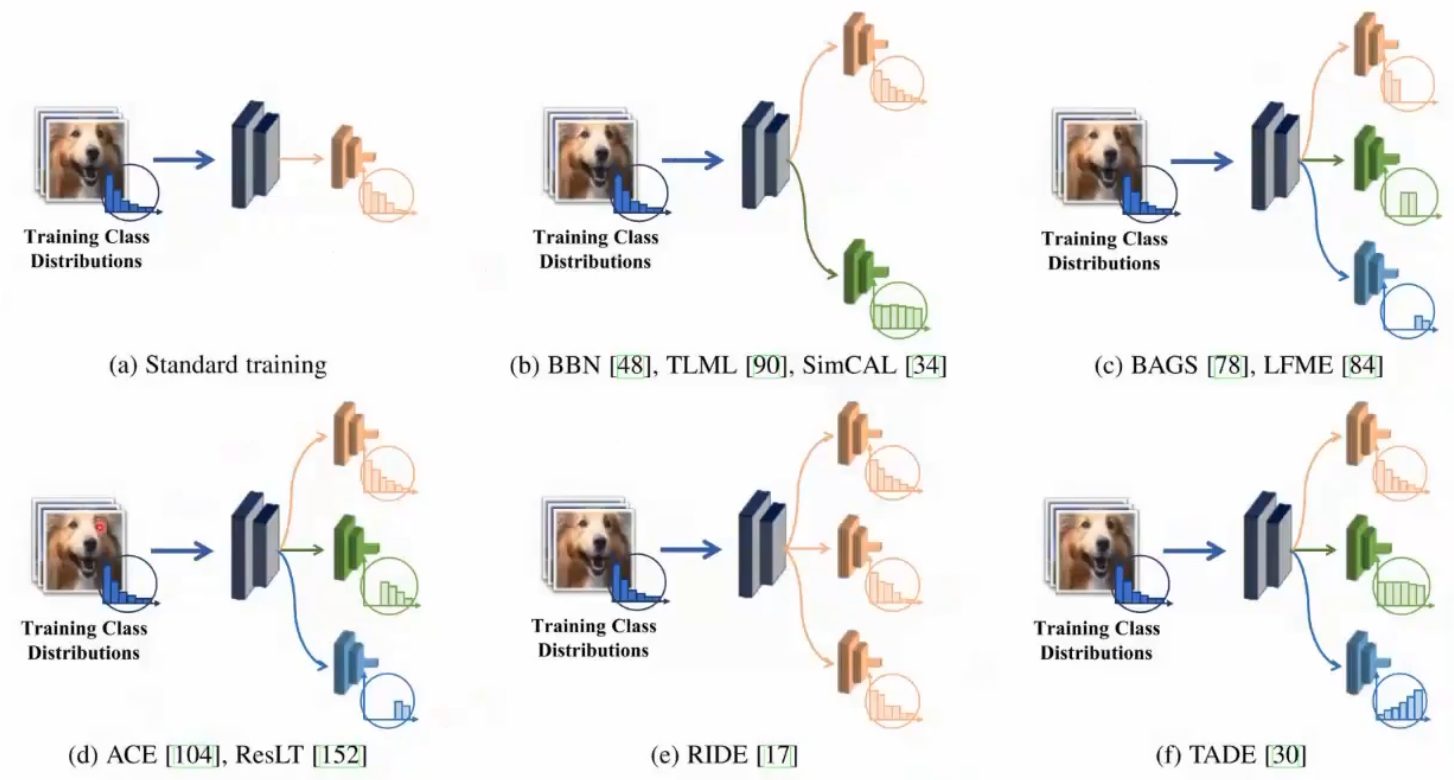
基本模型是一个,但是高层的分类器有不同设计
BAGS
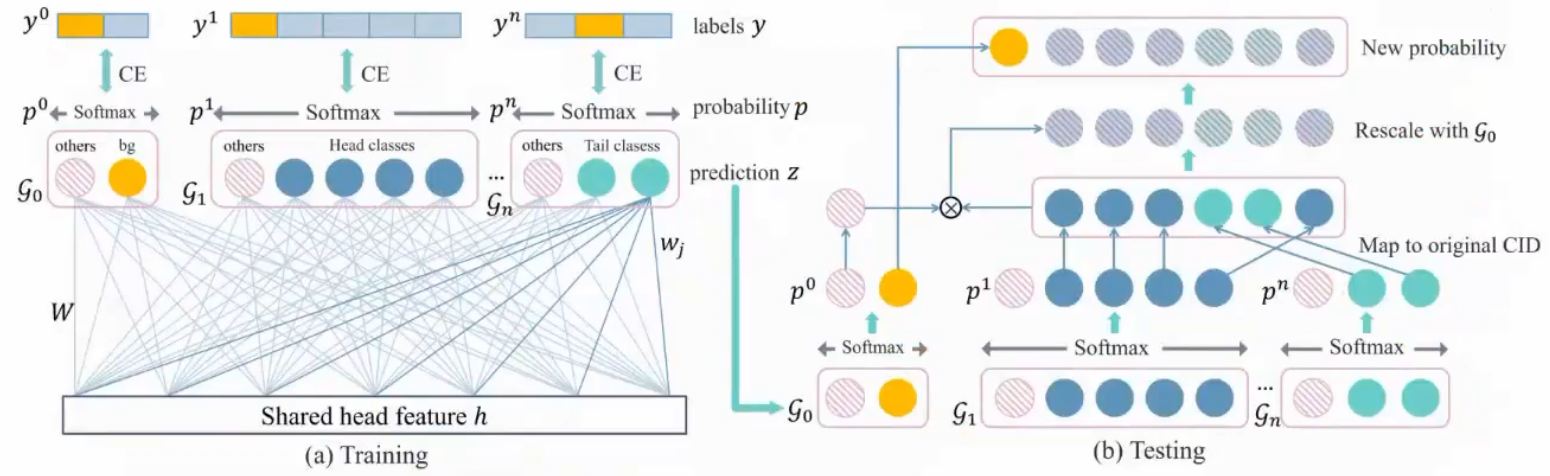
把样本按label数量按从大到小切成几个组,每个组里面的类别平衡就不会很悬殊,最后合并在一起看属于哪一类
ACE
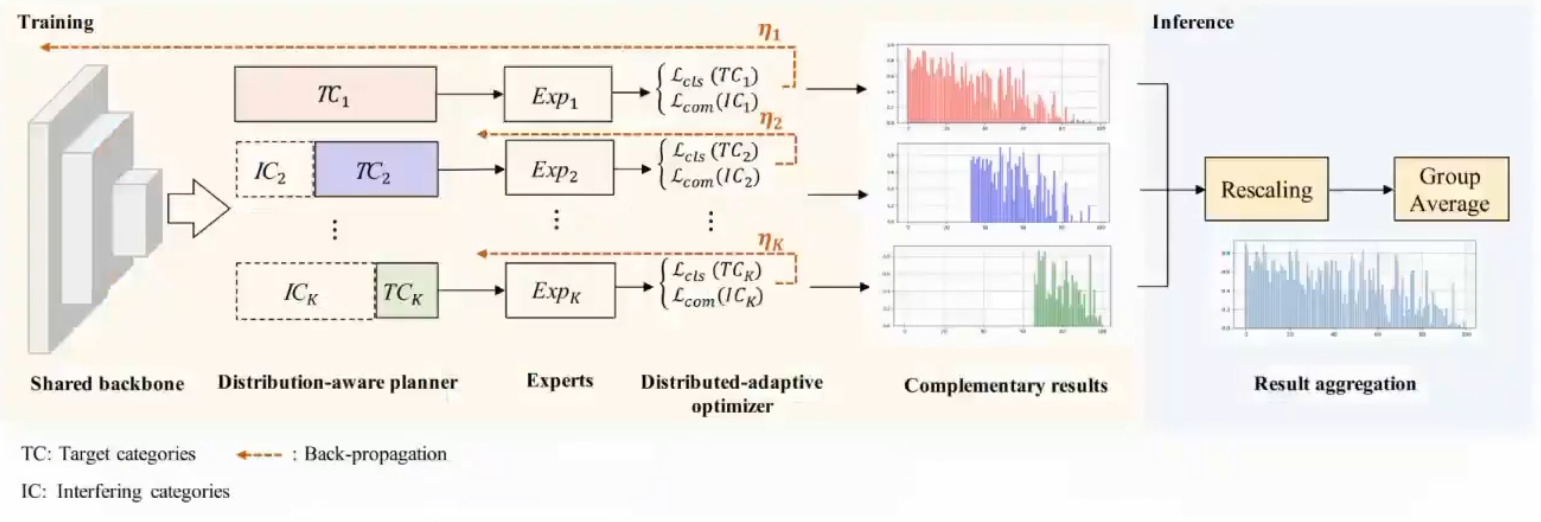
对数据做一些改变,第一个模型先学全部数据,第二个模型学中尾部数据,每个专家的经验会有一定差距,最后合并一块会得到相对平衡的结果
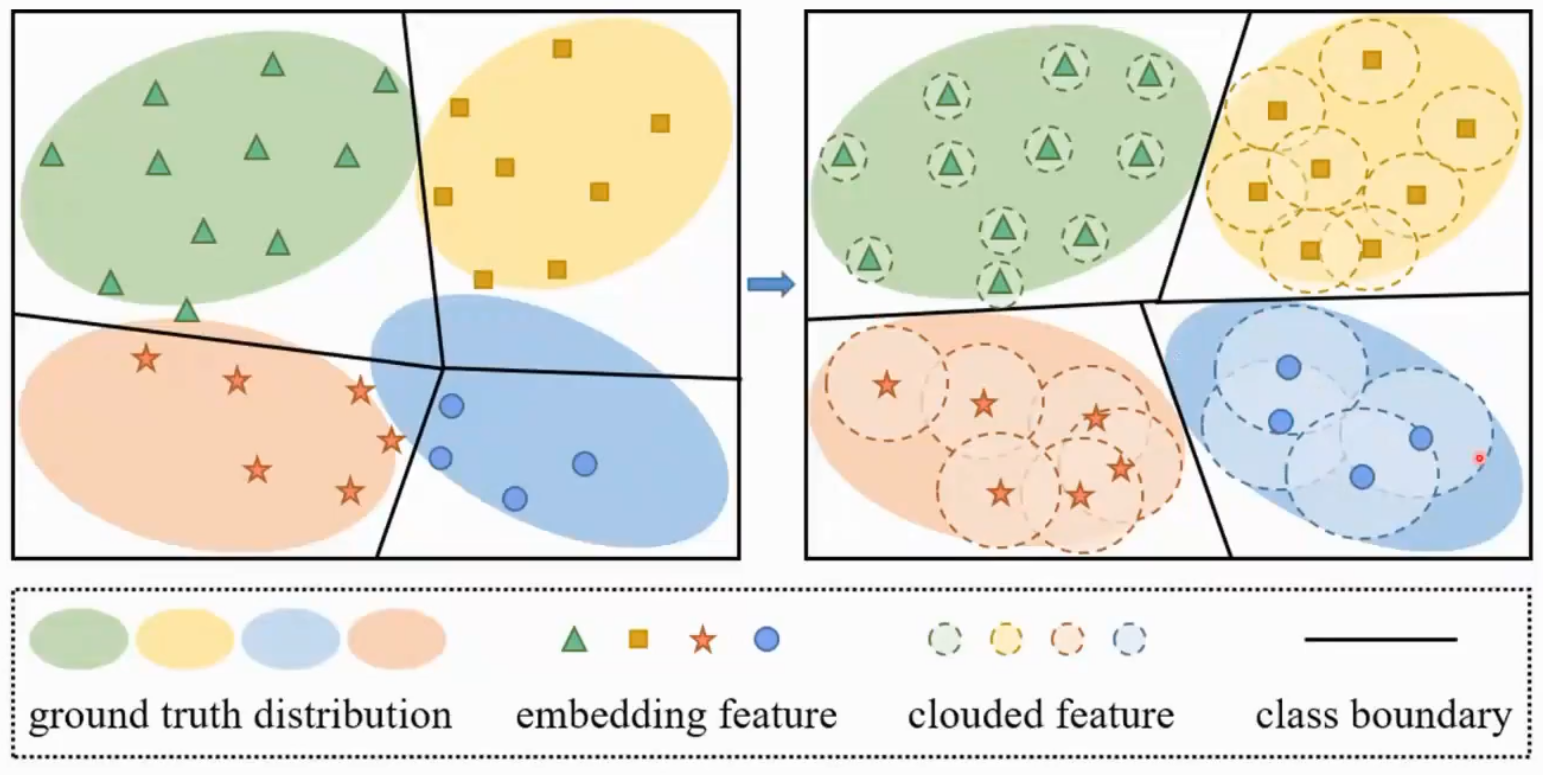
Gaussian Clouded Ligit (GCL)
头部类很容易因为softmax饱和而学不动了,给特征加上一部分扰动的高斯噪声,给最后的logit也加上一些扰动,每个类展开的空间就会变大
Federated Learning
数据不在server,而在每个client,每个本地模型更新后传到server再分发
Data Herogeneiy
联邦学习一个重要的关注点在于数据异构,比如摄像头在幼儿园和停车场的分布肯定是差异巨大的,意味着每个client可能是不同的分布,在server汇总时就会出现问题
- 每个client的数据不一样
- 每个client的训练类别数不一样
- 每个client的数据比例是不平衡的
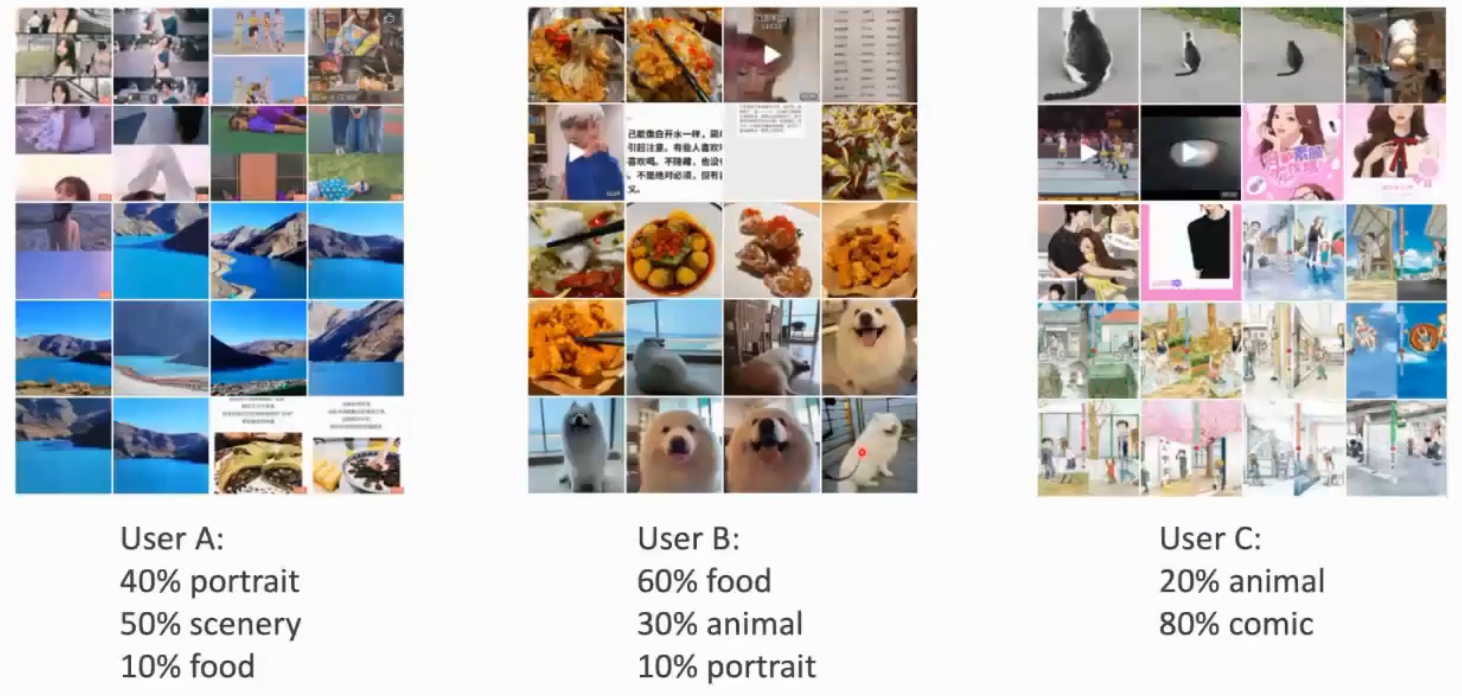
比如用户相册是一个很好的例子
Methods
FedProx
模型正则,每次全局模型本地更新时不要走得太远,加了一个模型更新的二范数,在一定程度上减缓模型异构的影响
$$
\text{min}_wF_k(w)+\frac{\mu}{2}||w-w^t||^2
$$
CCVR
数据异构对神经网络的每一层影响是不一样的,在高层影响很大,底层影响小
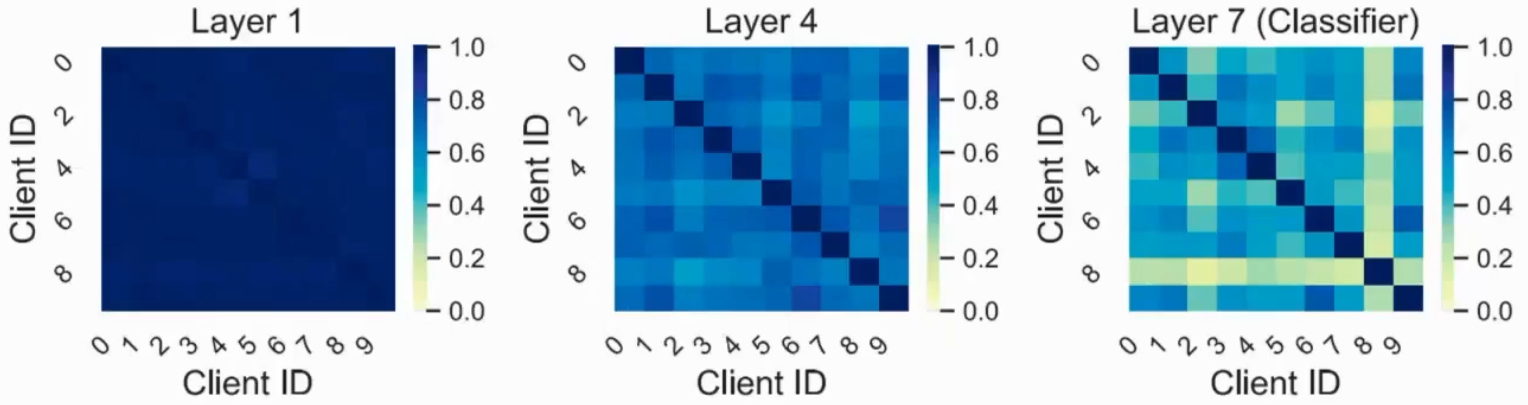
既然分类器不一样,那么就针对全局模型重新训练分类器,对每个client的数据上计算均值方差,server把所有均值方差重新采样再生成数据训练,但也存在两个问题
- 数据的特征和特征之间是相关联的,采样的话会把关联性采没了
- 需要知道每个client的类别分布(可能侵犯隐私)
CReFF
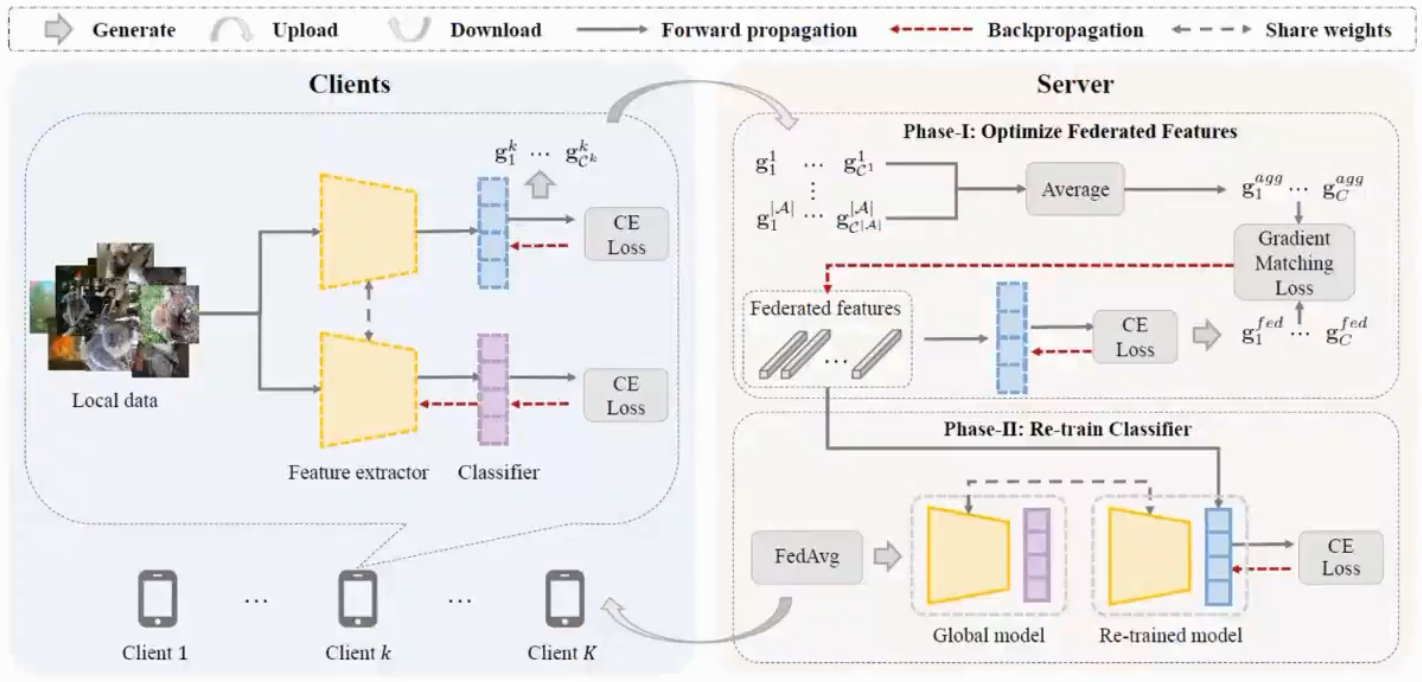
依然是重新训练分类器,基本思想是不用传均值方差,传梯度
server模型生成特征计算的梯度和client梯度算loss,只需要保证相似的梯度,不一的需要生成相似的特征
Noisy Label Learning
现实数据中的噪声一般会很大,以前传统模型比较简单,模型复杂度低,不容易完全拟合噪声,但是深度学习会
- 数据有噪声,把噪音数据跳出来
- 目标函数:正则
- 优化:模型
Noise Transition Matrix
假设某一类的标签很容易被标记成另外一类标签,如果能预先估计出转移矩阵,在预测过程中用到这个信息
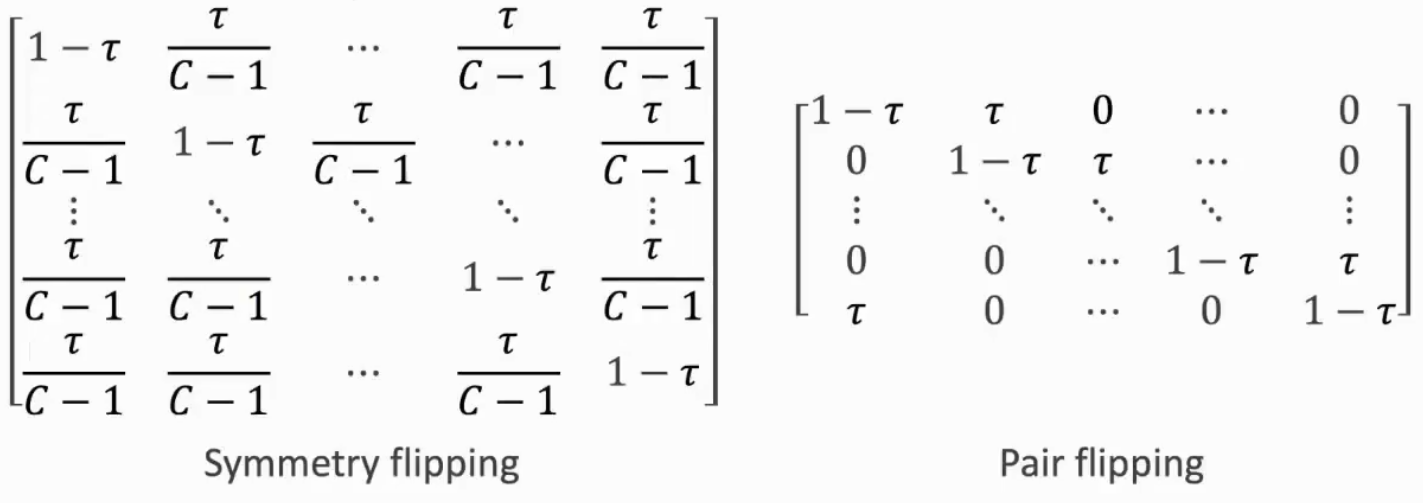
理论假设:每一类有一定概率平均预测成另一类或是两类之间的循环转换(猫分成狗,狗分成熊)
Adaption Layer
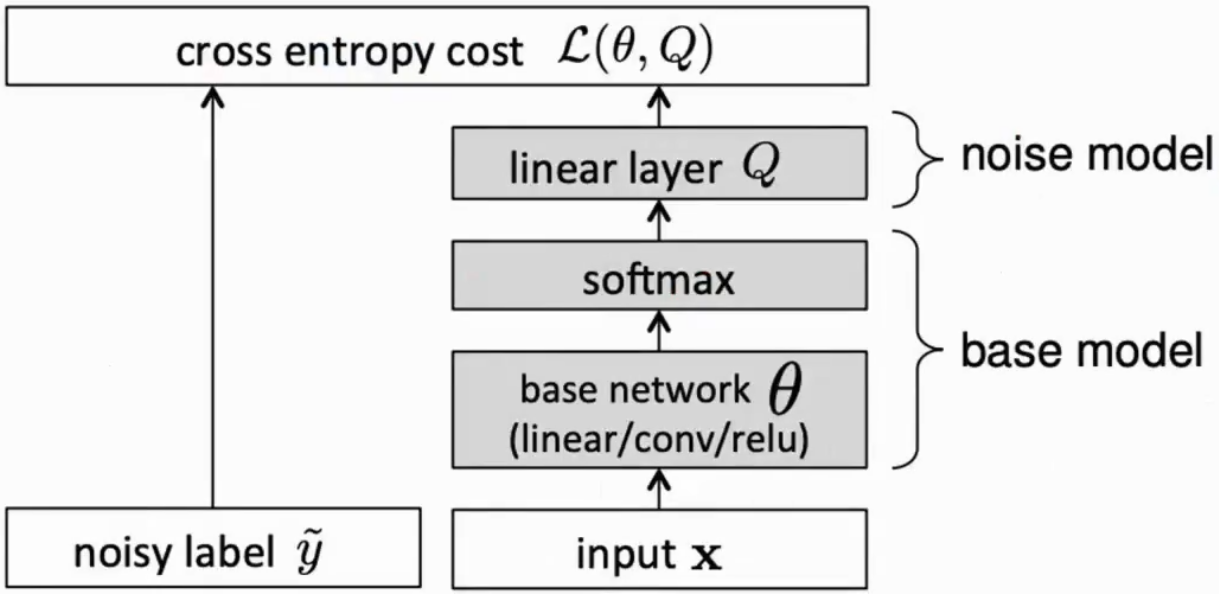
建立一个base model,把正常值算完,之后用noise model概率转移矩阵,把预测对的标签转移为打的错误标签,这样计算loss就没问题
Gold Loss Correction
要求一个包含很大量的噪声数据集,和少量的专家的精准数据集
用少量的专家数据集通过模型,把预测错的记录到矩阵,计算出概率转移矩阵
Meta Loss Correction
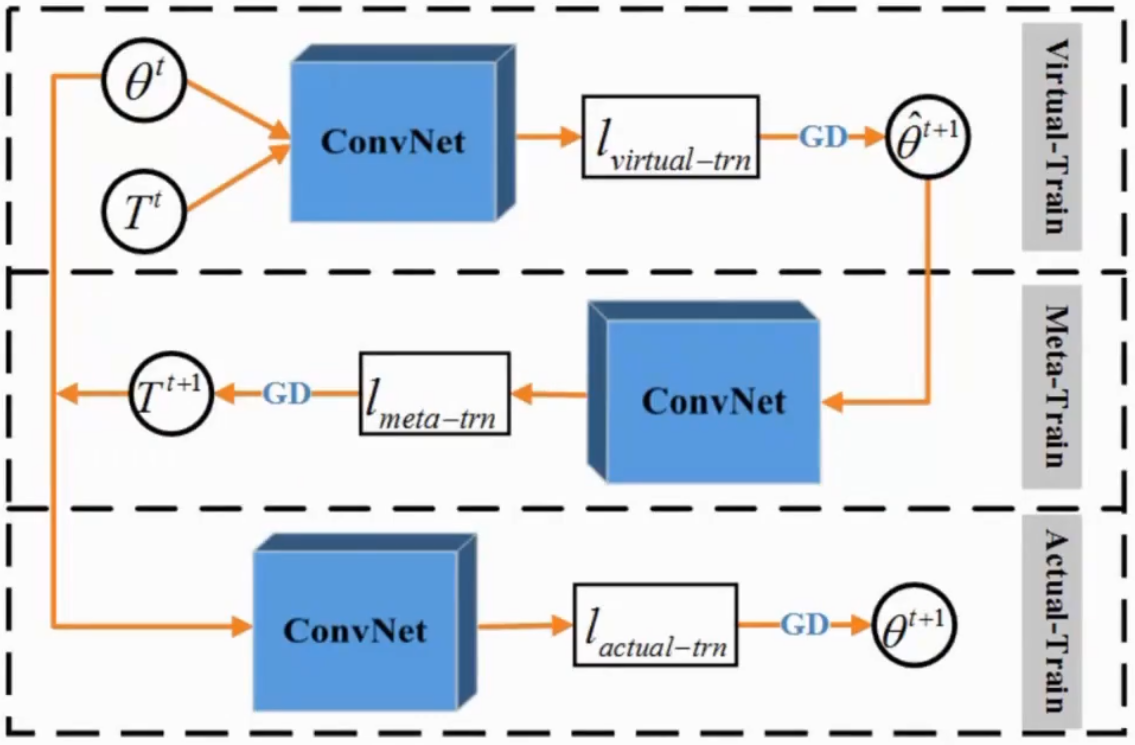
先在脏样本上训练临时模型,用元数据集(干净样本)更新初始模型
Objective-Based Methods
Auxiliary Regularization
$$
\Omega_{aux}(w)=||F_w||_g
$$
$F^T=[X_1,X_2,…,X_n]$ 表示一系列的包含数据特的对角矩阵,让他们的协方差尽量为0
强迫搜索如何通过少量的干净样本学习,直接丢弃噪音样本
Learning to Weight
用元学习的方法学习权重,噪声样本权重值大,干净样本权重值小
$$
\theta\leftarrow\theta-\alpha\nabla_\theta\sum_{i=1}^NF_\omega\big(l(\theta,x_i)\big)l(\theta,x_i)
$$
其中 $F_w(l(\theta,x_i))$ 输入训练loss输出对应的权重
New Loss Desgin
噪声样本的loss太大了,可以把梯度做一个简单的截断
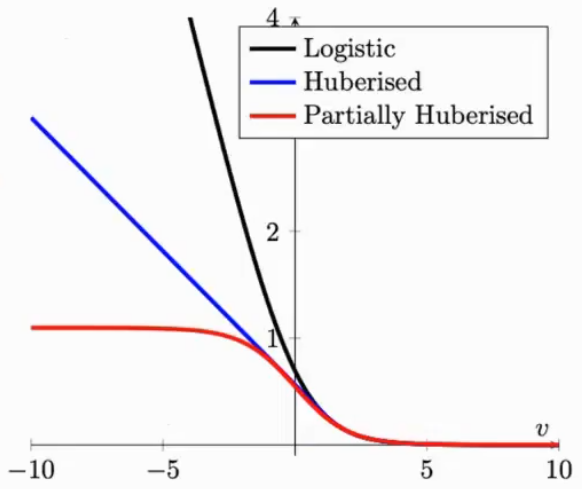 $$
l_\theta(x,y)=\begin{cases}-\tau p_\theta(x,y)+\log\tau+1&\text{if}p_\theta(x,y)\leq\frac{1}{\tau}\\\quad-\log p_\theta(x,y)&\text{otherwise}\end{cases}
$$
$$
l_\theta(x,y)=\begin{cases}-\tau p_\theta(x,y)+\log\tau+1&\text{if}p_\theta(x,y)\leq\frac{1}{\tau}\\\quad-\log p_\theta(x,y)&\text{otherwise}\end{cases}
$$
Optimization-Based Methods
利用了神经网络的记忆机制,神经网络在初期会学习简单样本,从下图来看模型的测试精度是下降后上升,噪声或困难样本在后面学
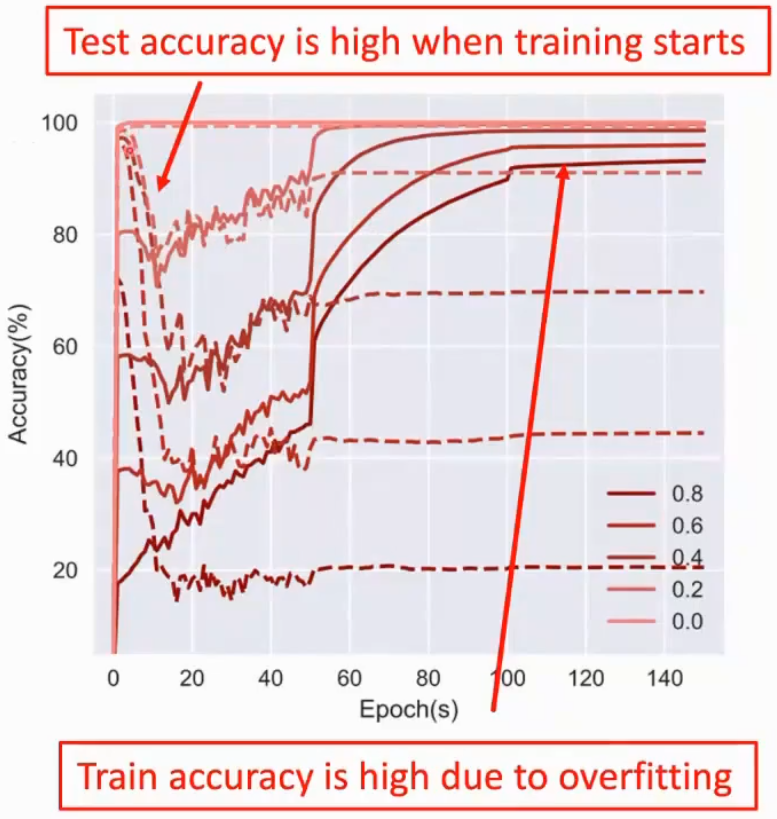
Small-Loss Trick
通过排序只学习简单样本,逃避困难样本
MentorNet
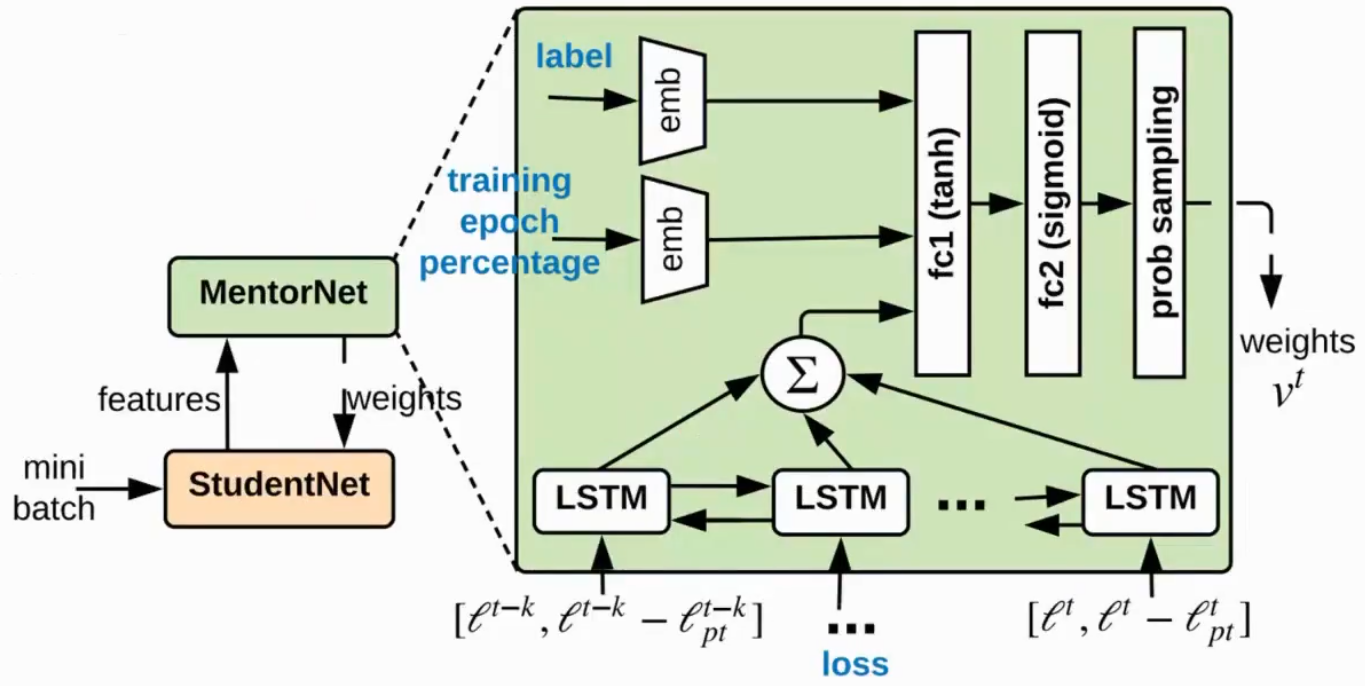
studentNet负责学习干净样本,MentorNet选出干净样本丢给StudentNet,能动态调整
Co-Teaching
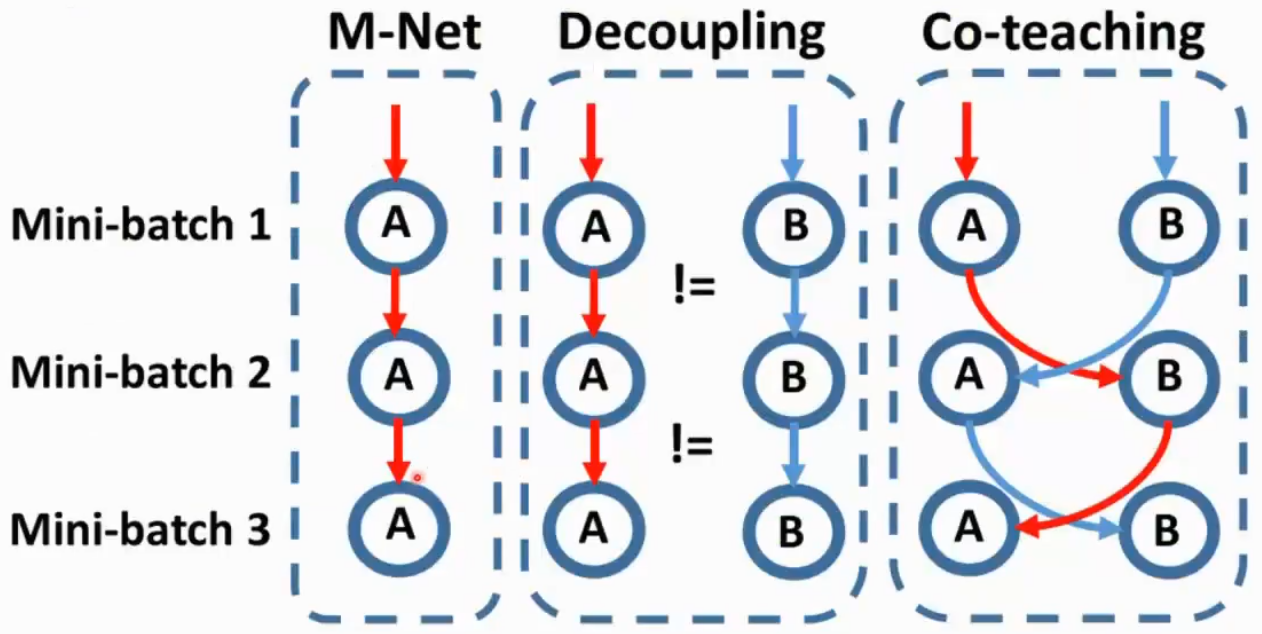
两个模型每个模型挑自己loss比较小的部分给对方学
Feature Direction: OOD Noise

样本只有100个类,但是新的数据不在这里面
Continual Learning
Problem Setting
- 数据不是一个批次来的,而是随着时间增长的
- 传统机器学习也叫做在线学习、增量学习、从数据流学习
- 在深度学习叫做持续学习、类增量学习或终身学习
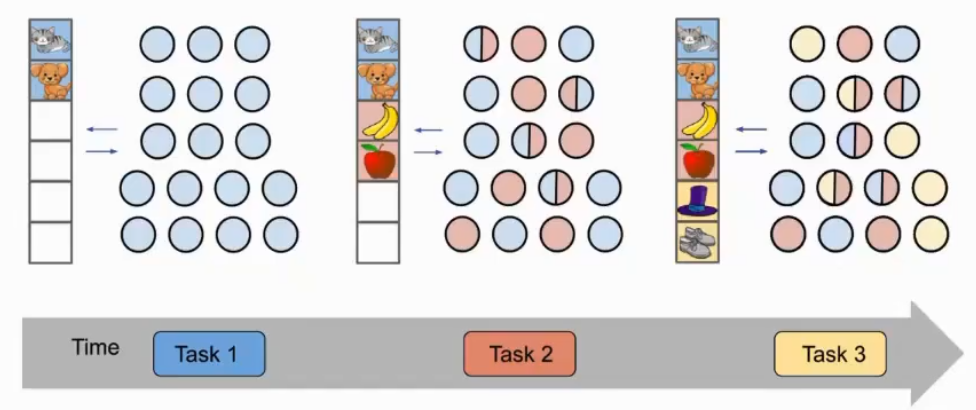
- 假设内存是有限的
- 分布偏移是可能的,比如标签或者标准发生了变化
- 在每个时间段进入的数据视作一个task
- 在历史所有的类上做分类
Catastrophic Forgetting
需要找到稳定性(记得以前的知识)和可塑性(收到新数据影响)的平衡,对于深度学习模型而言,可塑性是很容易的,这也叫做灾难性遗忘
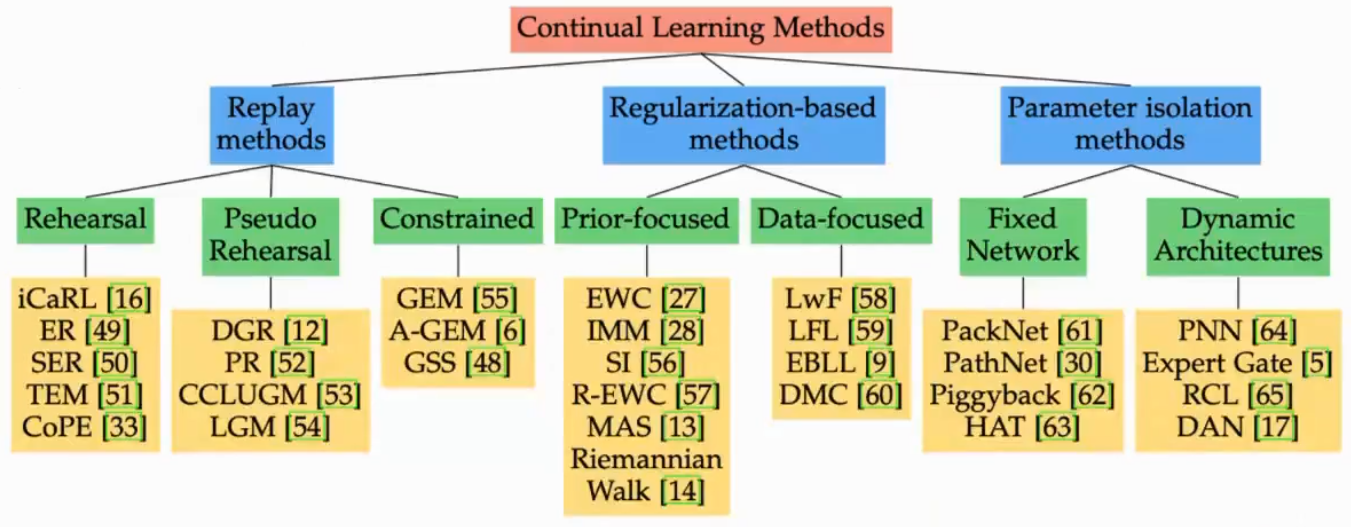
Replay-Based Methods
存每个过往任务具有代表性的样本,引发两个问题:
- 怎么选
- 怎么用
iCaRL
对每一类寻找特征均值(类中心)存下来
训练新数据新模型的时候两个loss相加,一个是新类上的损失,一个是老样本的蒸馏损失
GEM
学习新模型的时候在旧数据上的精度不能下降
Dataset Condensation
把数据尽量压缩到一些有代表性的样本同时保留尽量多的信息
Regularization-Based Methods
核心是模型不要在新任务上学习太好,不存数据存模型,新模型和老模型差异不大
Parameter Isolation Methods
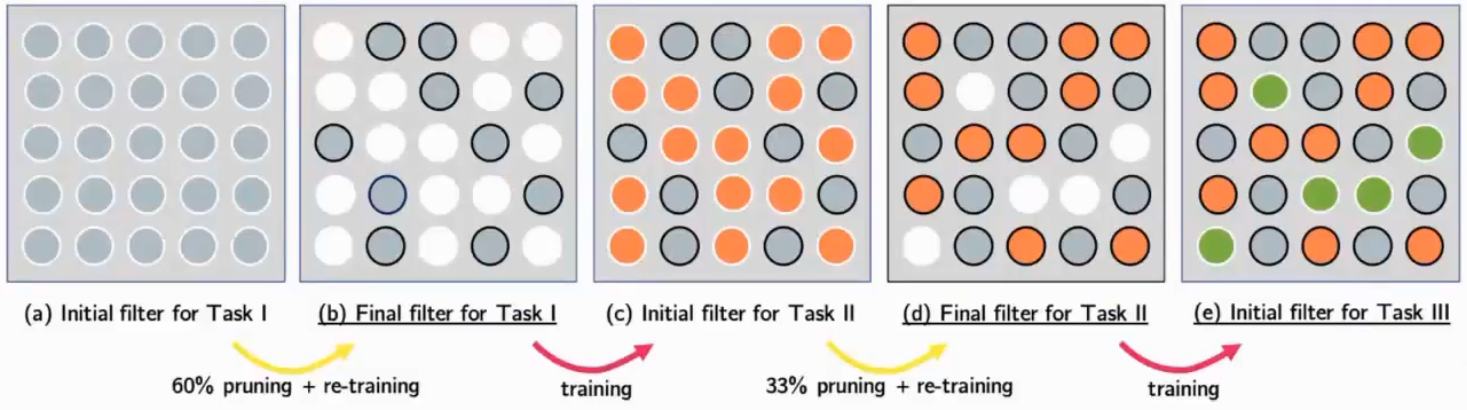
PackNet
模型能力大于学习的内容,有很多无效参数
每次学完对模型剪枝,但是不缩小模型大小,让空出来的参数学习新的任务,然后再剪枝
Hard Attention
每个attention跟任务相关