论文地址:LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
LlamaFactory:高效微调LLM的框架
Abstract
在下游任务上高效微调大模型是非常重要的,作者这里提出了LlamaFactory,可以通过内置的web UI,不需要代码就可以轻易微调100+LLM
Introduction

大型语言模型(LLMs)在推理能力和多种任务(如问答、机器翻译和信息提取)中表现卓越。近年来,LLMs在开源社区中得到广泛发展,例如 Hugging Face 的 LLM leaderboard 提供了超过 5000 个模型,便于用户利用 LLMs 的能力
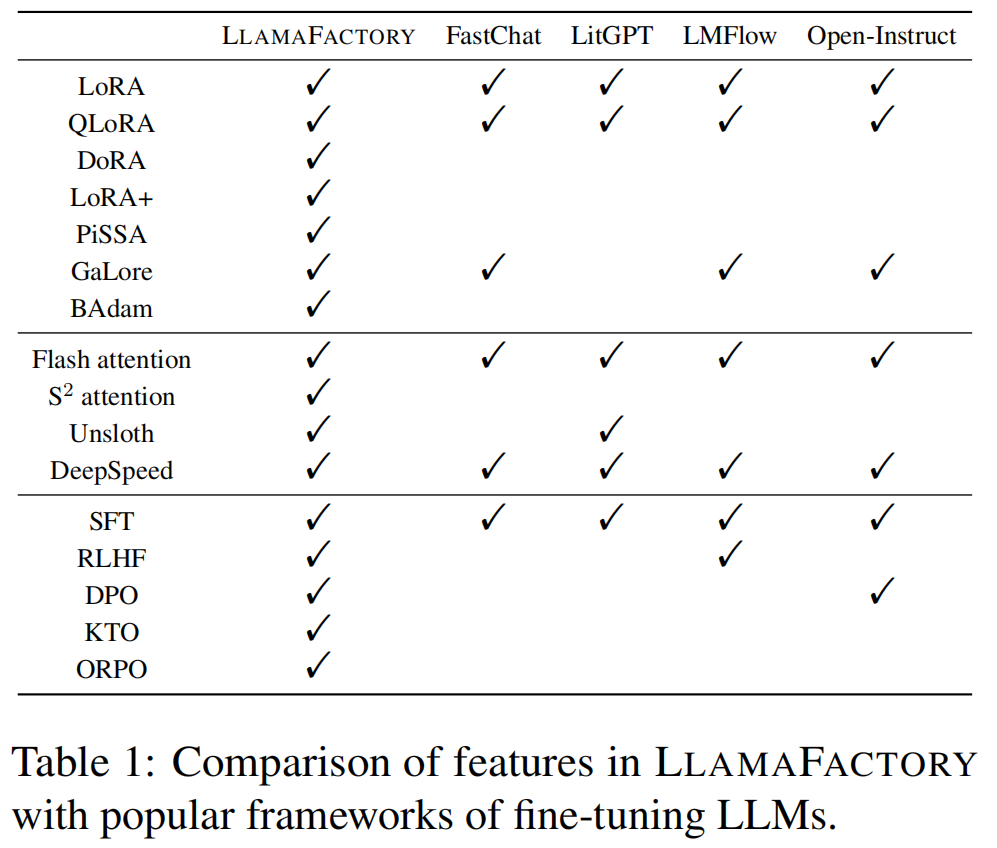
为了使LLMs适应下游任务,需要进行微调,但微调极大规模的模型参数需要大量计算资源,成为关键挑战。高效微调技术(如 LoRA、QLoRA 等)被提出以降低训练成本,但目前社区贡献了多种方法,缺乏统一的框架来支持这些技术的广泛适配与定制。
LLAMAFACTORY 框架:
- 作者提出了 LLAMAFACTORY,一个统一的框架,用于高效微调超过 100 种 LLMs。
- 框架整合了一系列最新的高效微调方法,能够以最小的资源和高吞吐量对模型进行微调。
- 提供两种用户友好的操作方式:命令行和图形化界面(LLAMABOARD),支持用户灵活定制和微调LLMs,几乎无需编写代码。
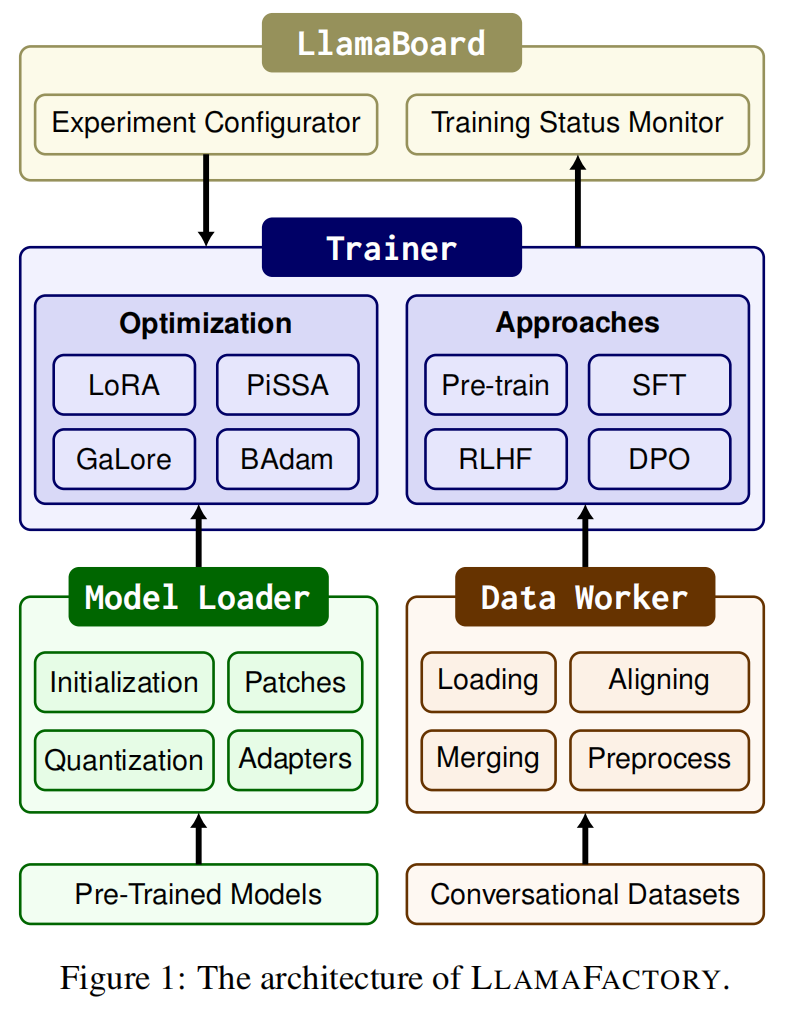
LLAMAFACTORY由三个核心模块组成:
- Model Loader:加载和管理预训练模型。
- Data Worker:处理和对齐不同格式的数据集。
- Trainer:应用高效的微调方法。
技术实现:
- 框架基于 PyTorch 和多个开源库(如 Transformers 和 PEFT)实现,提供了高抽象级别的开箱即用工具。
- 使用 Gradio 构建的 LLAMABOARD 图形界面使用户无需编写代码即可微调LLMs。
Efficient Fine-Tuning Techniques
Efficient Optimization
概述
高效优化技术的目标是以最小的资源成本调整LLMs的参数。这些技术通过冻结部分参数或引入低维适配器,减少计算复杂度。
技术细节
-
Freeze-tuning:
- 仅微调模型的少量参数,冻结大部分层。
- 通常只微调解码器层中少量参数,例如最后几层。
- 减少了需要更新的参数数量,从而降低资源消耗。
-
Gradient Low-Rank Projection (GaLore):
- 将梯度投影到低维空间中,支持全参数学习的同时显著节省内存。
- 适合大模型训练,既能保持性能又能减少内存开销。
-
BAdam:
- 基于 Block Coordinate Descent (BCD) 的方法,将参数分块处理以优化训练效率。
- 能高效优化大量参数。
-
Low-Rank Adaptation (LoRA):
- 冻结所有预训练权重,仅为指定层引入一对低秩矩阵,作为微调参数。
- 结合量化技术(如QLoRA)时,可以进一步减少内存使用。
-
QLoRA:
- 在量化权重的基础上进行LoRA微调。
- 使用4位量化和双重量化技术(如LLM.int8),显著降低了内存消耗。
-
DoRA:
- 将预训练权重分解为大小和方向两部分,仅更新方向部分以提升性能。
- 比LoRA更高效,适用于复杂的微调场景。
-
LoRA+:
- 针对LoRA的优化,通过解决低秩分解的次优问题,进一步提升性能。
-
PiSSA (Principal Singular Values and Singular Vectors Adaptation):
- 基于预训练权重的主成分初始化适配器,收敛速度更快。
Efficient Computation
概述
高效计算技术的目标是减少LLMs训练过程中的时间或内存需求,通过硬件优化和计算方法提升效率。
技术细节
-
Mixed Precision Training:
- 使用混合精度(如float16和bfloat16)进行训练,减少内存占用。
- 在不显著降低模型精度的情况下提高计算效率。
-
Activation Checkpointing:
- 在前向传播中保存部分中间结果,并在反向传播时重新计算未保存的部分,以降低内存使用。
-
Flash Attention:
- 一种硬件友好的注意力机制,减少了Attention层的I/O开销,提高计算效率。
-
S2Attention (Shifted Sparse Attention):
- 针对长上下文的LLMs,利用稀疏注意力机制减少内存消耗。
-
Quantization:
- 通过权重的低精度表示(如4位或8位)降低模型的内存需求。
- 支持多种后训练量化方法,如GPTQ、AWQ和AQLM。
-
Unsloth:
- 利用Triton库实现LoRA的反向传播,减少浮点运算(FLOPs),加速梯度下降。
- 提升了LoRA微调的效率。
LLAMAFACTORY 将上述优化和计算技术无缝集成到框架中,显著提升了LLMs微调的效率
LlamaFactory Framework
Model Loader
Model Loader 负责管理模型的初始化和微调,具体包括以下功能:
-
Model Initialization(模型初始化):
- 使用 Transformers 的 Auto 类(如 AutoModelForCausalLM 和 AutoTokenizer)加载预训练模型和分词器。
- 支持自动调整嵌入层大小并初始化新参数。
- 利用 RoPE(旋转位置编码)的比例因子扩展上下文长度。
-
Model Patching(模型补丁):
- 使用“猴子补丁”技术为模型添加新功能,如 S²Attention。
- 原生支持 Flash Attention,优化计算效率。
- 在 DeepSpeed ZeRO stage-3 下优化 MoE(专家混合)模型,防止动态层过度分区。
-
Model Quantization(模型量化):
- 支持 4 位或 8 位动态量化(如 LLM.int8 和 QLoRA 的双量化)。
- 兼容多种量化方法(如 GPTQ、AWQ 和 AQLM),但仅支持适配器方法对量化权重进行微调。
-
Adapter Attaching(适配器挂载):
- 自动检测适配器插入的位置(如所有线性层)以优化收敛性能。
- 支持多种适配器方法(如 LoRA、DoRA 和 PiSSA)。
- 使用 Unsloth 替换反向传播以加速训练。
-
Precision Adaptation(精度适配):
- 根据硬件计算能力调整浮点精度(如 bfloat16 或 float16)。
- 在混合精度训练中保留所有可训练参数为 float32,以提高稳定性。
Data Worker
Data Worker 提供了一整套数据处理流水线,使得不同任务的数据能够被统一格式化处理。
-
Dataset Loading(数据集加载):
- 基于 Datasets 库加载本地或远程数据集。
- 使用 Arrow 格式减少内存开销,支持数据流模式,避免下载整个数据集。
-
Dataset Aligning(数据对齐):
- 提供数据描述规范,将多种数据格式(如 Alpaca、ShareGPT 等)标准化为统一结构。
-
Dataset Merging(数据合并):
-
提供高效的合并方法:
- 非流模式下直接拼接数据集。
- 流模式下交替读取数据以保持随机性。
-
-
Dataset Preprocessing(数据预处理):
- 提供多种聊天模板(chat templates)来适配不同模型。
- 默认仅计算生成部分的损失,支持序列压缩技术以减少训练时间。
Trainer
Trainer 是框架的核心模块之一,用于整合高效微调方法和训练机制。
-
Efficient Training(高效训练):
- 支持最新的高效微调方法(如 LoRA+、GaLore 和 BAdam)。
- 通过模块化设计,使不同任务能够灵活应用这些方法。
- 使用 Transformers 和 TRL 库的训练器支持预训练、指令调优、偏好优化等任务。
-
Model-Sharing RLHF(模型共享的 RLHF):
- 提出一种新方法,使 RLHF(基于人类反馈的强化学习)能够在消费者设备上完成。
- 通过动态切换适配器,单个预训练模型即可同时充当策略、价值、参考和奖励模型。
-
Distributed Training(分布式训练):
- 结合 DeepSpeed 实现数据并行,通过 ZeRO 优化器减少内存消耗。
Utilities
-
Model Inference(模型推理):
- 支持基于 Transformers 和 vLLM 的流式解码,提供高吞吐量推理服务。
- 提供 OpenAI 风格的 API,方便集成至应用中。
-
Model Evaluation(模型评估):
- 支持多种任务的自动评估(如 MMLU、CMMLU 和 BLEU)。
- 提供文本相似度计算和人类评估功能。
LLAMABOARD: A Unified Interface for LLAMAFACTORY
LLAMABOARD 是 LLAMAFACTORY 的图形界面,允许用户通过 Web 界面无代码地定制微调和评估流程。
-
Easy Configuration(易配置):
- 默认提供推荐参数,用户可通过界面预览和验证数据集。
-
Monitorable Training(可监控训练):
- 提供实时的训练日志和损失曲线,帮助用户分析训练进程。
-
Flexible Evaluation(灵活评估):
- 支持自动和人类评估,便于用户测量模型能力。
-
Multilingual Support(多语言支持):
- 支持界面本地化,目前支持英语、俄语和中文。
Empirical Study
Training Efficiency
实验设置
- 数据集:使用 PubMed 数据集,其中包含 3600 万条生物医学文献记录,抽取约 40 万个 token 构建训练语料
- 实验条件:学习率:10−5、Token 批大小:512、优化器:8位 AdamW、精度:bfloat16、使用激活检查点技术减少内存占用、Freeze-tuning:仅微调模型最后3层解码器、GaLore:秩设置为128,缩放因子设置为2.0、LoRA/QLoRA:在所有线性层附加适配器,秩为128,alpha 为256、硬件:单张 NVIDIA A100 40GB GPU、Flash Attention 在所有实验中启用;LoRA 和 QLoRA 还启用了 Unsloth。

- 在 Gemma-2B 上,QLoRA 的内存消耗为 5.21 GB,吞吐量为 3158.59 tokens/s,PPL 为 10.46。
- 在 Llama2-13B 上,GaLore 的 PPL 为 5.72,比 LoRA 和 QLoRA 更优,但内存需求较高
Fine-Tuning on Downstream Tasks
实验设置
-
任务:
- CNN/DM:摘要生成任务
- XSum:极端摘要生成任务
- AdGen:广告文本生成任务
-
数据集划分:
- 每个任务使用 2000 个训练样本和 1000 个测试样本。
- 训练集和测试集互不重叠。
-
评估指标:
-
使用 ROUGE 分数(包括 ROUGE-1、ROUGE-2 和 ROUGE-L)评估生成文本质量。
-
实验条件:
- 学习率:10−5、批大小:4、最大输入长度:2048、优化器:8位 AdamW、硬件:NVIDIA A100 40GB GPU、LoRA 和 QLoRA 的适配器设置与训练效率实验相同
-
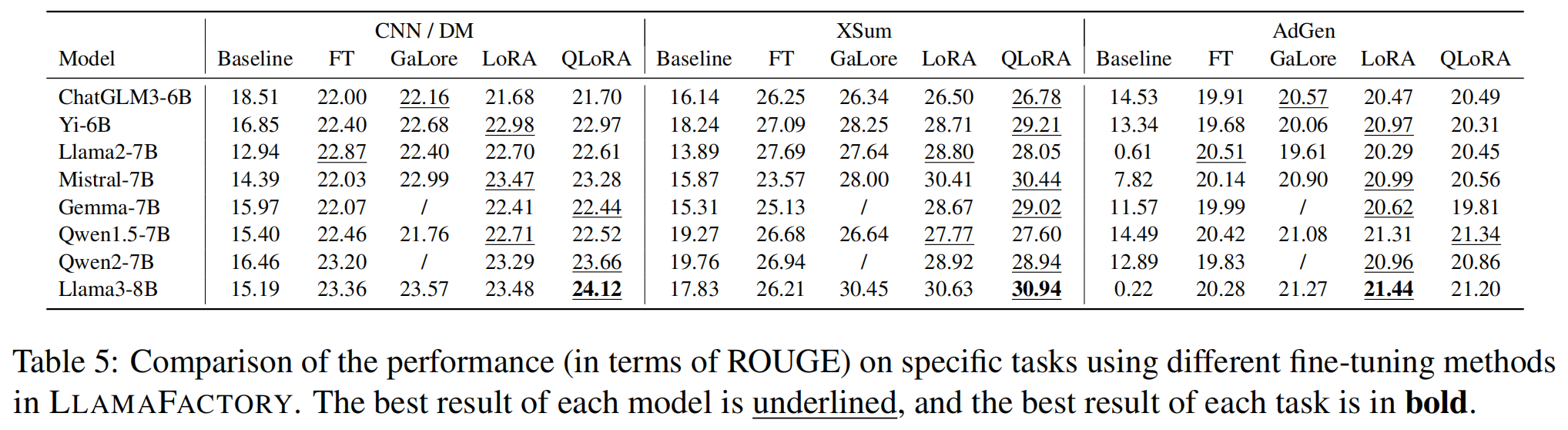
最佳微调方法:
- LoRA 和 QLoRA 在大多数任务和模型中表现最佳。
- 例如,在 XSum 和 AdGen 任务中,Llama3-8B 使用 QLoRA 获得了最高 ROUGE 分数。
-
不同模型的表现:
- Llama3-8B 是所有模型中性能最好的,在多个任务中实现了最高分数。
- Yi-6B 和 Mistral-7B 在同等规模的模型中表现出竞争力。
-
任务相关性:
- QLoRA 在生成任务上表现稳定,尤其适用于高资源受限的场景。
总结
-
训练效率:
- QLoRA 和 LoRA 的内存效率和吞吐量显著高于传统的全参数微调方法。
- 在大模型中,GaLore 通过优化梯度表现出更优的 PPL。
-
下游任务适配性:
- LoRA 和 QLoRA 展现了极强的适应能力,尤其是在小模型和资源受限场景中。
- 不同模型在特定任务中表现存在差异,Llama3-8B 在多个任务中占据优势。
-
LLAMAFACTORY 的有效性:
- 框架的高效微调方法不仅提升了训练效率,还能很好地适配下游任务,验证了其在多场景下的实用性。

