IgBert-IgT5:抗体继续预训练语言模型
Abstract
抗体是免疫系统中用于识别和中和抗原的蛋白质,广泛应用于治疗领域,随着下一代测序技术的发展,已经收集了数十亿条抗体序列,但由于数据量巨大且复杂,其在优化治疗设计中的应用受到限制。研究提出了 IgBert 和 IgT5 两个新的抗体特异性语言模型,能够同时处理成对(重链和轻链)和未成对的抗体可变区序列。模型训练基于来自 Observed Antibody Space (OAS) 数据集的超过 20 亿条未成对序列和 200 万条成对序列。研究证明,这些模型在抗体工程相关的设计和回归任务中,超越了现有的抗体和蛋白语言模型,IgBert 和 IgT5 展现了在序列恢复、表达水平预测和结合亲和力预测任务上的卓越性能。
Introduction
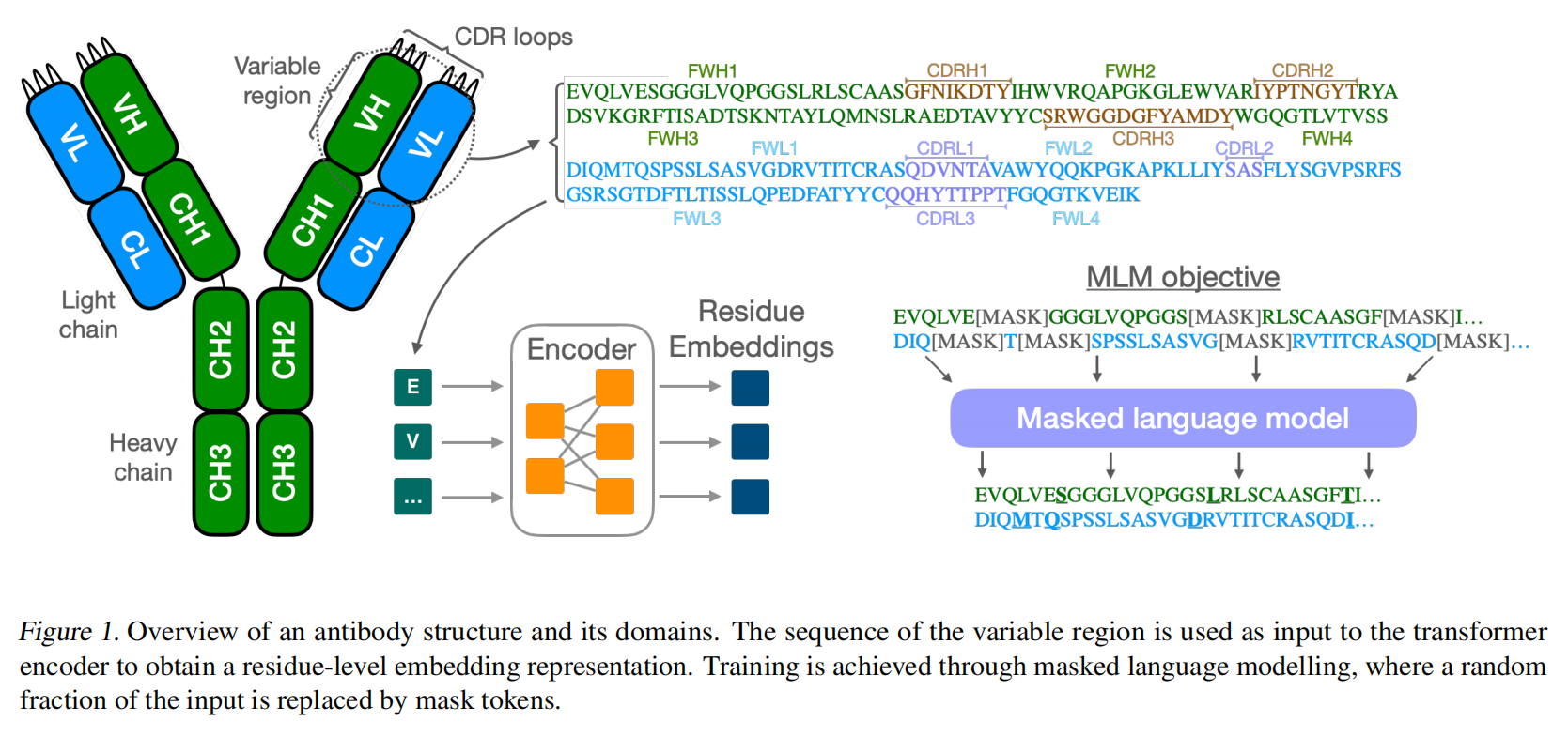
抗体是免疫系统的重要组成部分,通过识别和中和抗原(如细菌、病毒和毒素)保护机体。抗体分子呈对称的 Y 形结构,由两条轻链(light chains)和两条重链(heavy chains)组成。可变区(variable region)是抗体特异性识别抗原的关键部分,其中的 互补决定区(CDR) 尤其重要,特别是 重链第三 CDR(CDRH3),其多样性和结构复杂性在抗原识别中起关键作用。
随着下一代测序(NGS)技术的发展,科学家能够快速获取大规模抗体序列,揭示抗体多样性,数据的海量性使得传统的生物信息学方法(如序列比对和基序搜索)难以全面分析这些序列。
蛋白语言模型(Protein Language Models,PLMs)受到自然语言处理领域的启发,通过无监督学习方法,从大量未标注序列中学习抗体的复杂模式。通常,这些模型基于 掩码语言建模(masked language modeling, MLM) 训练,随机掩盖序列中的部分氨基酸残基,然后让模型预测被掩盖的残基。
这些模型已经在许多蛋白质设计任务中表现出色,包括:恢复缺失残基、生成新序列、预测结构、识别功能属性(如结合位点和热稳定性)
针对抗体的语言模型能够更精准地学习抗体的特定序列特性,例如通过训练 成对的重链和轻链序列,模型可以捕捉跨链的交互特性。
然而,大多数现有的抗体语言模型:
- 仅基于未成对序列
- 或者依赖于从通用蛋白模型微调的策略(尽管这种方法较少计算成本,但可能无法捕捉抗体特异性特征)。
本文旨在开发 IgBert 和 IgT5 两种抗体特异性语言模型:
- IgBert 是基于 BERT 架构的双向编码器。
- IgT5 是基于 T5 的文本生成模型,可以统一处理文本到文本的问题。
研究的关键创新点:
- 在 Observed Antibody Space (OAS) 数据集的 超过 20 亿条未成对序列 和 200 万条成对序列 上训练模型。
- 探讨这些模型在序列恢复、结合亲和力预测、表达水平预测等任务上的性能
Models
两种模型均使用 掩码语言建模(MLM) 作为训练目标
序列编码与掩码:
-
序列被解析为氨基酸类型的标记(tokens),通过分隔符(BERT 使用
[SEP],T5 使用</s>)区分重链和轻链。 -
输入序列的部分氨基酸残基会被随机掩盖,IgBert 和 IgT5 的掩码策略分别如下:
-
IgBert:
- 每个序列中有 15% 的残基被选为掩码位置。
- 这些残基中,80% 被替换为 mask token,10% 被替换为随机残基,10% 保持不变。
-
IgT5:
- 同样掩盖 15% 的残基,但以连续片段形式替换为单一的 sentinel token。
- 与 BERT 不同,T5 的目标是重建完整序列。
-
Data preparation
数据来源
-
模型的训练数据来自 Observed Antibody Space (OAS) 数据库,主要包含:
- 超过 20 亿条未成对序列:包括可变区的重链和轻链序列。
- 超过 200 万条成对序列:包括重链和轻链的可变区序列。
-
数据集以人类的免疫抗体序列为主。
数据处理流程
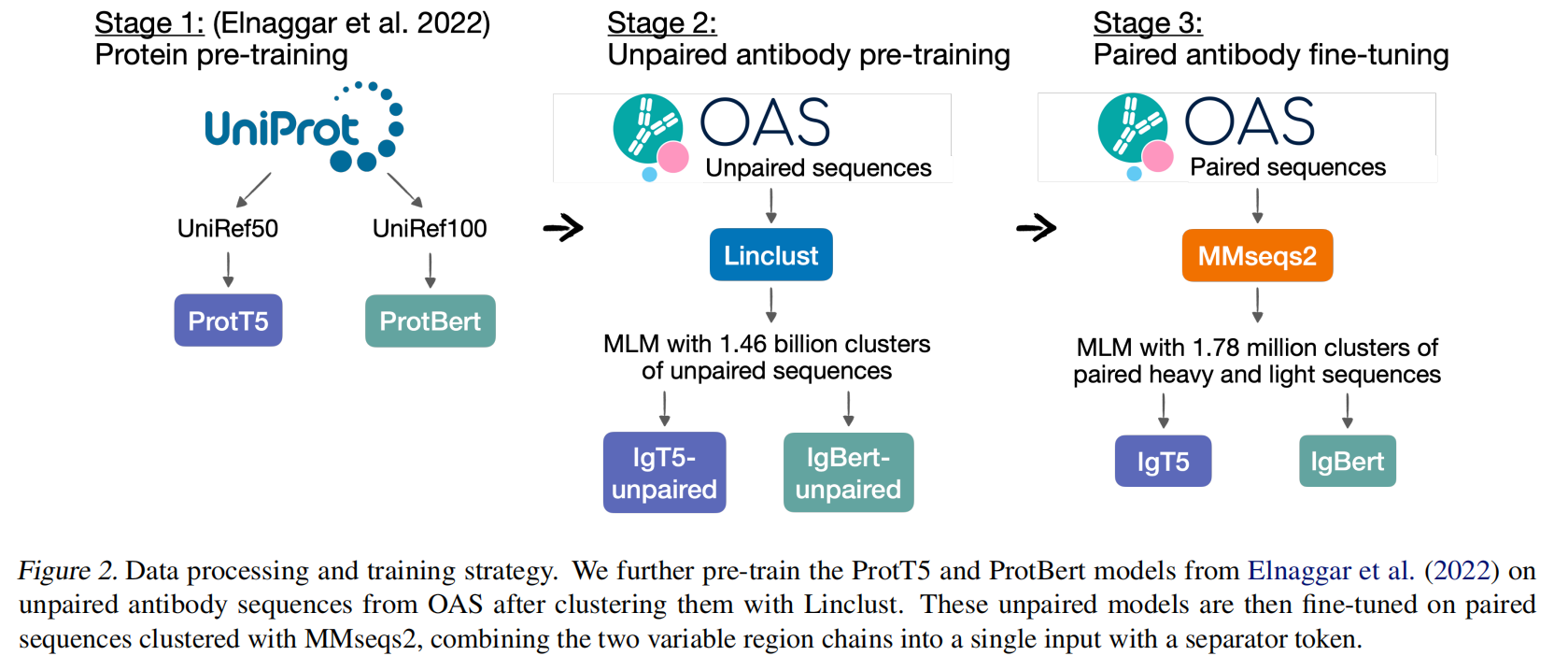
数据准备分为两阶段:未成对序列预训练数据准备 和 成对序列微调数据准备。
(1) 未成对序列的预训练数据准备
-
去重:
- 数据库中的序列去重,最终保留 2,097,593,973 条唯一序列。
-
聚类:
- 使用 Linclust 算法对序列进行聚类,确保训练、验证和测试集中不存在相似序列。
- 聚类采用 95% 序列相似度阈值,最终生成 1,456,516,479 个聚类簇。
-
数据划分:
- 从聚类簇中随机选择 40 万个簇构建验证集和测试集(各占 20 万个簇)。
- 其余 1,416,516,479 个聚类簇构成训练集,总计包含 2,040,122,161 条序列。
- 测试和验证集中各包含 20 万条代表性序列。
(2) 成对序列的微调数据准备
-
去重与聚类:
-
OAS中有 2,038,528 成对序列
-
针对成对的重链和轻链序列,采用 MMseqs2 聚类算法,相似度阈值同样为 95%。
-
聚类操作基于重链和轻链的拼接序列。
-
结果包括:
- 1,777,722 个聚类簇(训练集、验证集和测试集)。
- 其中,随机选择 40,000 个簇作为验证集和测试集(各占 20,000 个簇)。
- 剩余簇用于训练,总计包含 1,992,786 条唯一成对序列。
-
测试和验证集各包含 20,000 条代表性序列。
-
-
输入格式:
- 将重链和轻链的序列拼接成单一输入,并用分隔符(
[SEP]或</s>)区分。
- 将重链和轻链的序列拼接成单一输入,并用分隔符(
Pre-training on unpaired sequences
使用32张A100 GPUs,DeepSpeed ZeRO Stage 2训练,每条序列的长度被填充或截断为 200
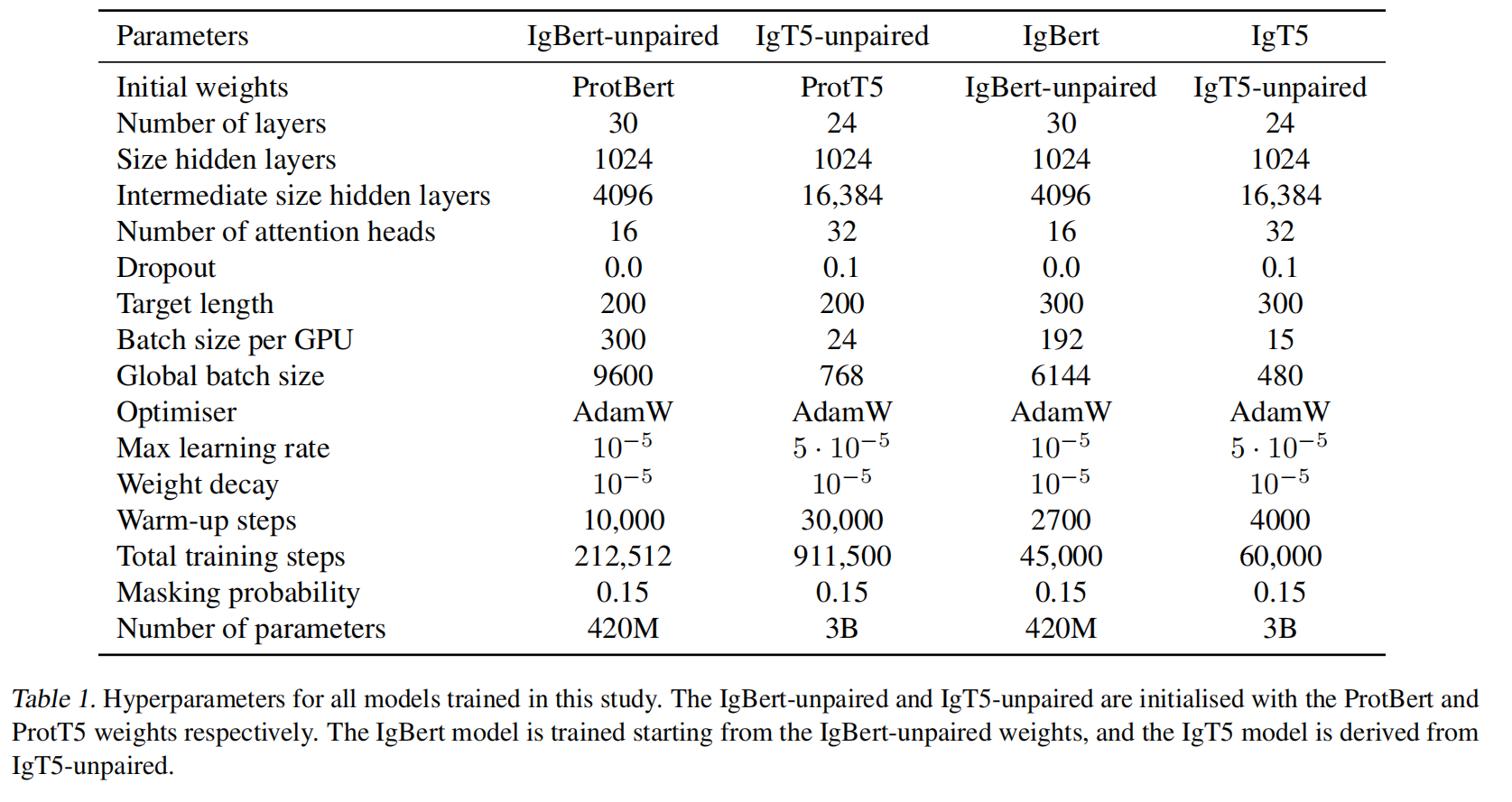
IgBert-unpaired
- 模型初始化:IgBert-unpaired 使用 ProtBert 预训练权重初始化。
- 训练集:所有属于未成对 OAS 训练聚类的数据。
- 批量大小:每个 GPU 的批量大小为 300。全局批量大小为 9600。
- 训练轮数:训练了总计 212,512 步,对应完整训练集的一个 epoch。
- 学习率和调度:最大学习率为 10−5。10,000 步的学习率warm up。
- 训练时间:约 66 小时。
IgT5-unpaired
- 模型规模:IgT5 架构的参数量远大于 IgBert,因此占用更多的计算资源和显存。由于计算限制,训练仅选用了训练簇的代表性序列。
- 模型初始化:IgT5-unpaired 使用 ProtT5 预训练权重初始化。
- 训练集:仅使用约 700M 条训练簇中的代表性序列。
- 批量大小:每个 GPU 的批量大小为 24。全局批量大小为 768。
- 训练轮数:总计训练 911,500 步,对应半个 epoch。
- 学习率和调度:最大学习率为 5×10−55 \times 10^{-5}5×10−5(相对于 IgBert 的学习率更高)。30,000 步的学习率warmup。
- 训练时间:约 9 天。
- 掩码策略:T5 模型采用单一片段掩码(maximum span length 为 1),与 MLM 目标类似,但包括额外的序列重建项。
Fine-tuning on paired sequences
- 成对序列输入:重链和轻链序列被拼接成单一输入序列,之间插入一个分隔符(IgBert 使用
[SEP],IgT5 使用</s>)。 - 输入长度:成对序列的输入长度固定为 300,以适应重链和轻链的结合,输入长度的增加导致批量大小需要减小以适应显存限制。
避免灾难性遗忘(catastrophic forgetting):
-
为防止模型在微调成对数据时丧失对未成对序列的表征能力,微调过程中使用了混合批次:
- 每个批次中包含未成对和成对序列。
- 成对序列和未成对序列的比例为 1:2。
-
未成对序列随机选自预训练数据的训练集。
-
训练设置:
- 除了输入长度和批次构建,其他设置(如优化器和学习率调度)与预训练阶段保持一致。
IgBert
-
模型初始化:使用 IgBert-unpaired 的预训练权重。
-
批量大小:每个 GPU 的批量大小为:128 条未成对序列,64 条成对序列。
-
训练步骤:总计 45,000 步,相当于 46 个 epoch(成对数据完整通过 46 次)。
-
学习率调度:学习率线性暖启动,warmup步数为 2,700 步(约 3 个 epoch)。
-
目标函数:
-
继续使用掩码语言建模(MLM)目标:
- 15% 的氨基酸残基被掩盖。
- 掩盖残基中,80% 替换为 mask token,10% 替换为随机残基,10% 保持不变。
-
IgT5
- 模型初始化:使用 IgT5-unpaired 的预训练权重。
- 批量大小:每个 GPU 的批量大小为:10 条未成对序列,5 条成对序列。
- 训练步骤:总计 60,000 步,相当于 5 个 epoch。
- 学习率调度:学习率线性暖启动,warmup步数为 4,000 步。
- 目标函数:与未成对序列的预训练目标一致
Results
Sequence recovery
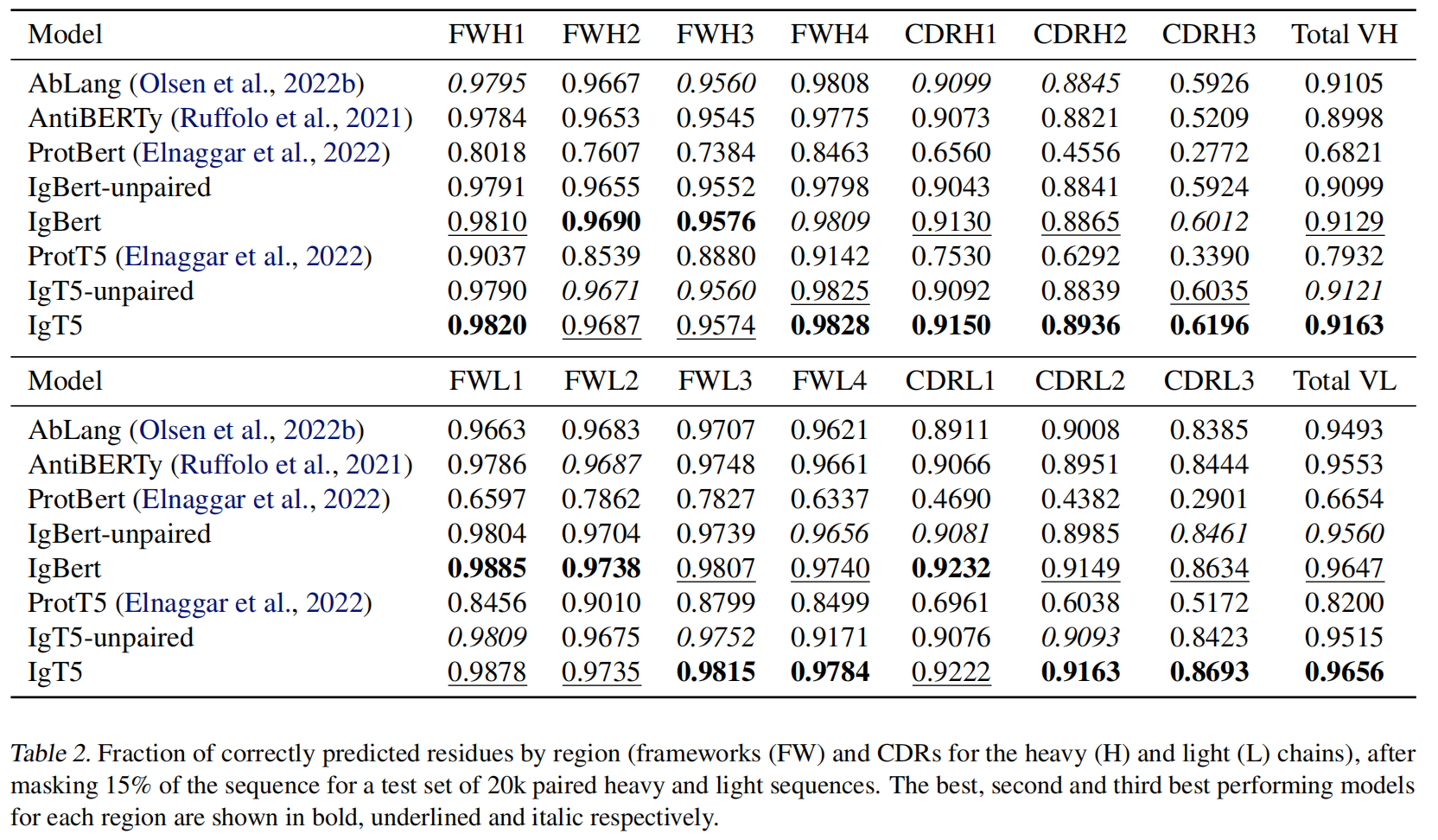
随机掩盖测试集成对序列的 15% 残基,让模型恢复被掩盖的残基。评价指标是每个区域(框架区和互补决定区,CDR)的正确预测残基比例。
- IgT5 和 IgBert 的性能显著优于现有模型,特别是在 CDR 区域。
- 在框架区的恢复上,两种模型均表现出色。
Binding affinity and expression
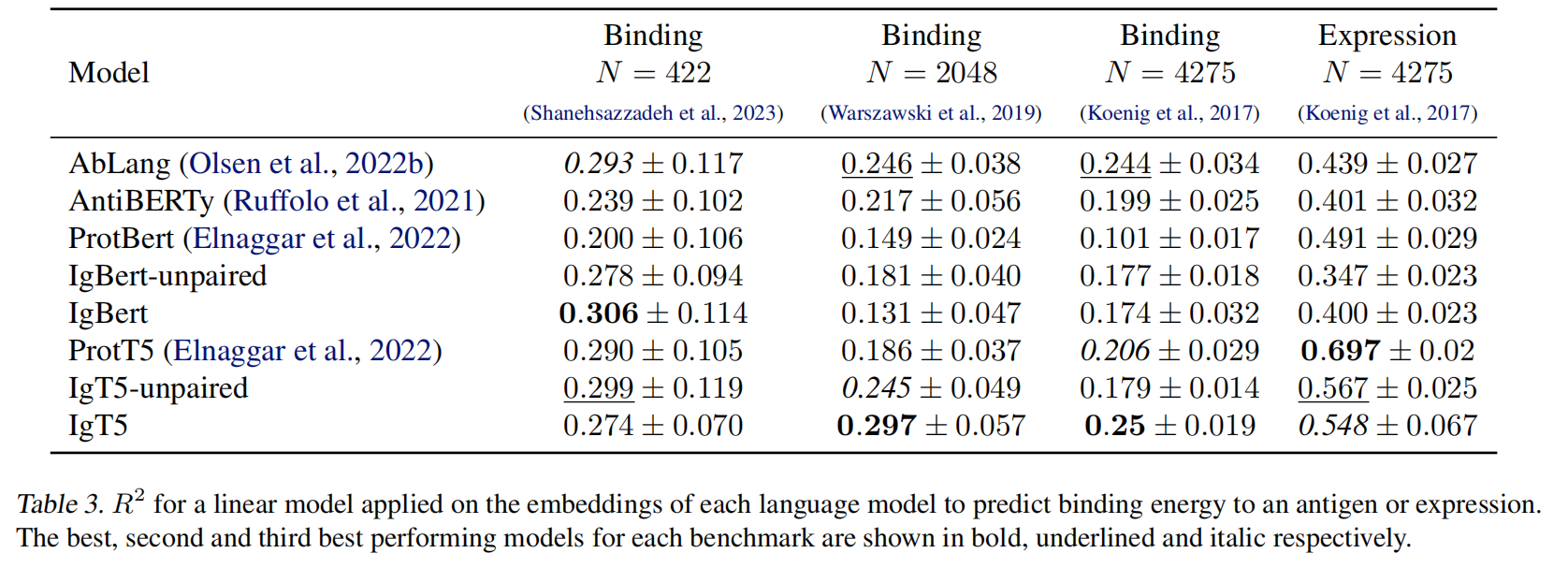
使用语言模型的嵌入作为特征,通过线性回归预测实验测量的结合亲和力和表达水平。
-
数据来源:
- 结合亲和力数据:三个数据集,总计约 6700 条数据。
- 表达水平数据:一个数据集,总计 4275 条数据。
结合亲和力预测:
- IgT5 和 IgBert 表现最佳:IgT5 在某些结合亲和力数据集上表现显著优于其他模型,表明成对数据微调的有效性。
- 一般蛋白语言模型(如 ProtBert 和 ProtT5)的表现较弱。
表达水平预测:
- ProtT5 表现最佳:在表达任务中,IgT5 和 IgBert 的表现不如 ProtT5,表明广义蛋白模型在涉及更广泛进化信息的任务上具有优势。
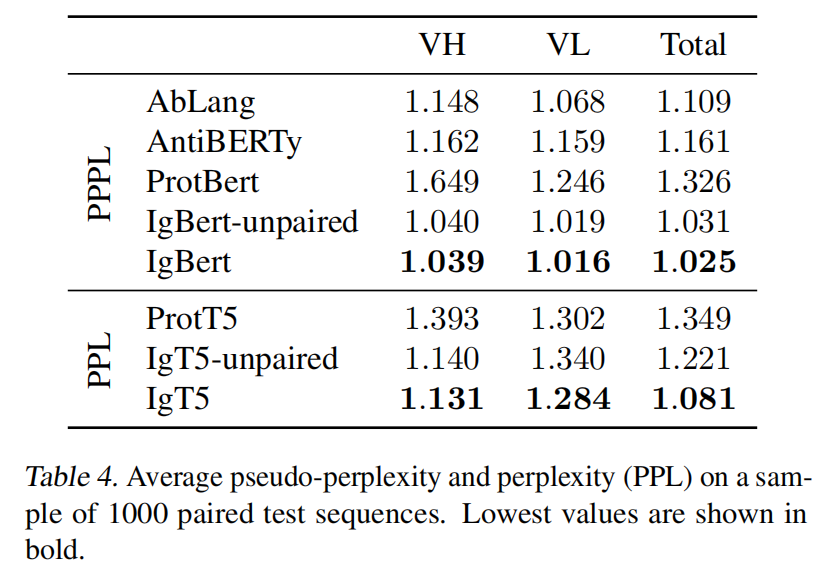
Perplexity
使用 1000 条随机选取的成对测试序列进行评价

