Movie Gen:meta视频生成
Abstract
Movie Gen是一系列的生成式基座模型,能够生成1080p的高清视频,基于指令的视频编辑,或基于用户图像的视频生成。最大的模型是30B,最大的上下文长度73K,大概16秒每秒16帧
3 Joint Image and Video Generation
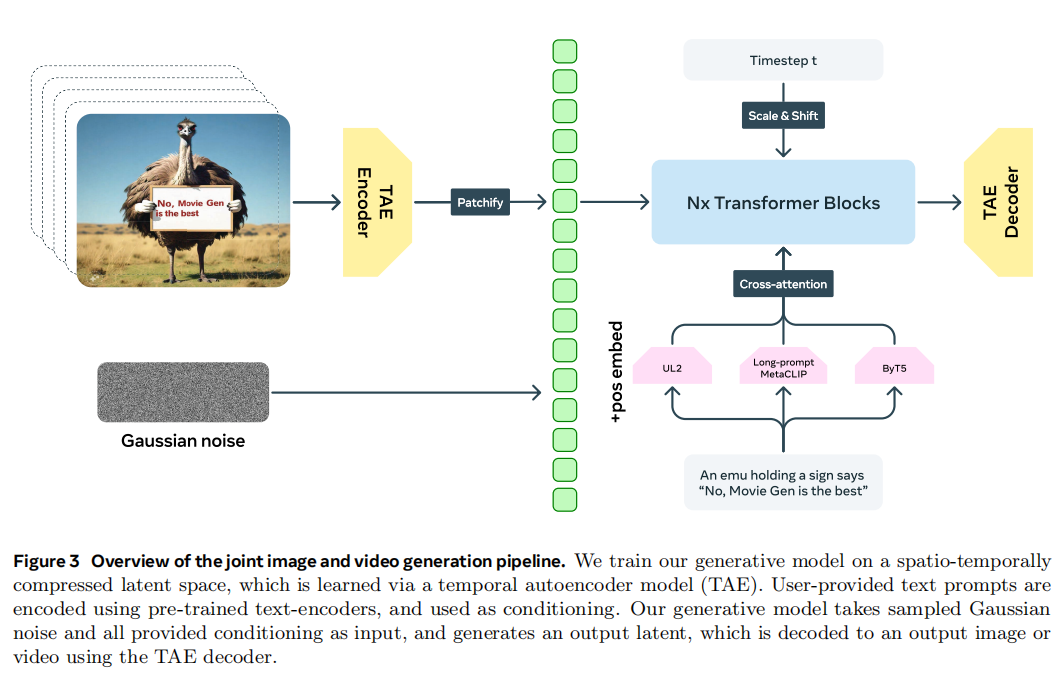
3.1 Image and Video Foundation Model
因为视频的分辨率和帧率相比于图像都太大了,为了效率,要把RGB的pixel-space video压缩到隐空间,压缩的越小越好
3.1.1 Temporal Autoencoder (TAE)
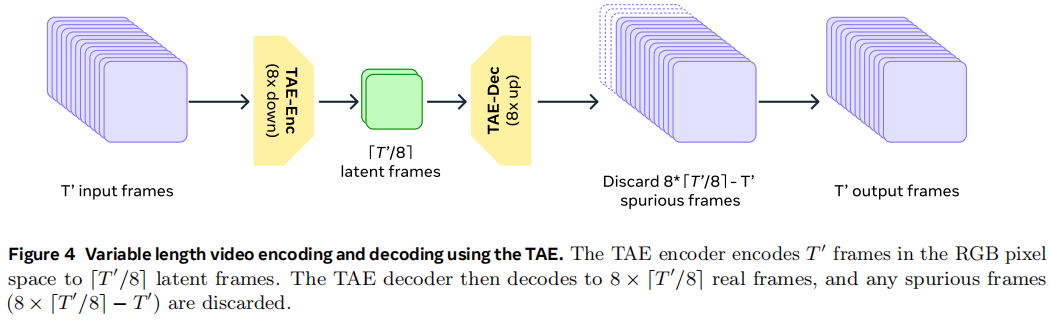
在时间、长度和高度上都压缩为原来的1/8
TAE architecture. 在每个2D的基础上加了一个时间的1D的卷积就能处理视频了,在时间层面用stride为2的卷积做下采样。TAE先用pre-trained imgae autoencoder,然后把temporal维度加上,去inflate model。
3.1.2 Training Objective for Video and Image Generation
用的是flow matching训练,给定一个视频样本的latent space $X_1$,time-step t采样为 $t\in [0,1]$,以及一个noise样本 $X_0\sim N(0,1)$,对于训练样本 $X_t$ 的构造,模型需要训练去预测速度 $V_t=\frac{dX_t}{d_t}$ ,也是就是学习从训练样本 $X_t$ 直接迁移到视频样本 $X_1$,这里是使用的OT(optimal transport path)
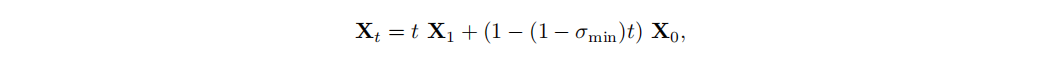
其中 $\sigma_{min}=10^{-5}$
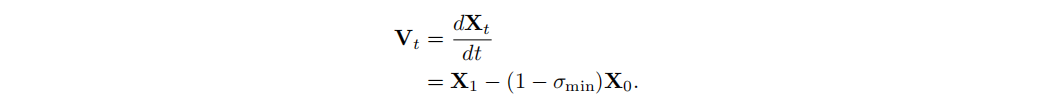
最后的loss就是
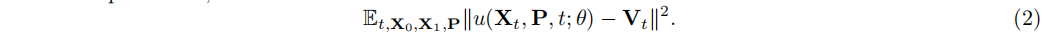
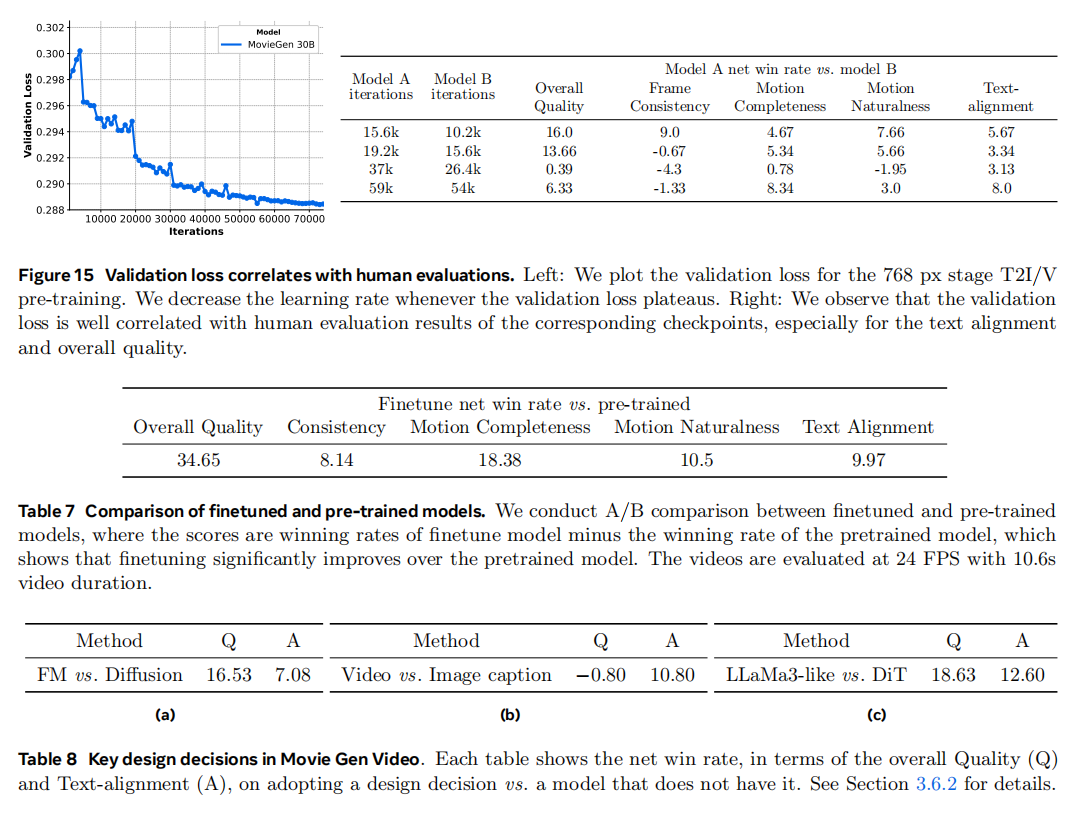
表8展示了flow matching和diffusion的训练哪种更好
3.1.3 Joint Image and Video Generation Backbone Architecture
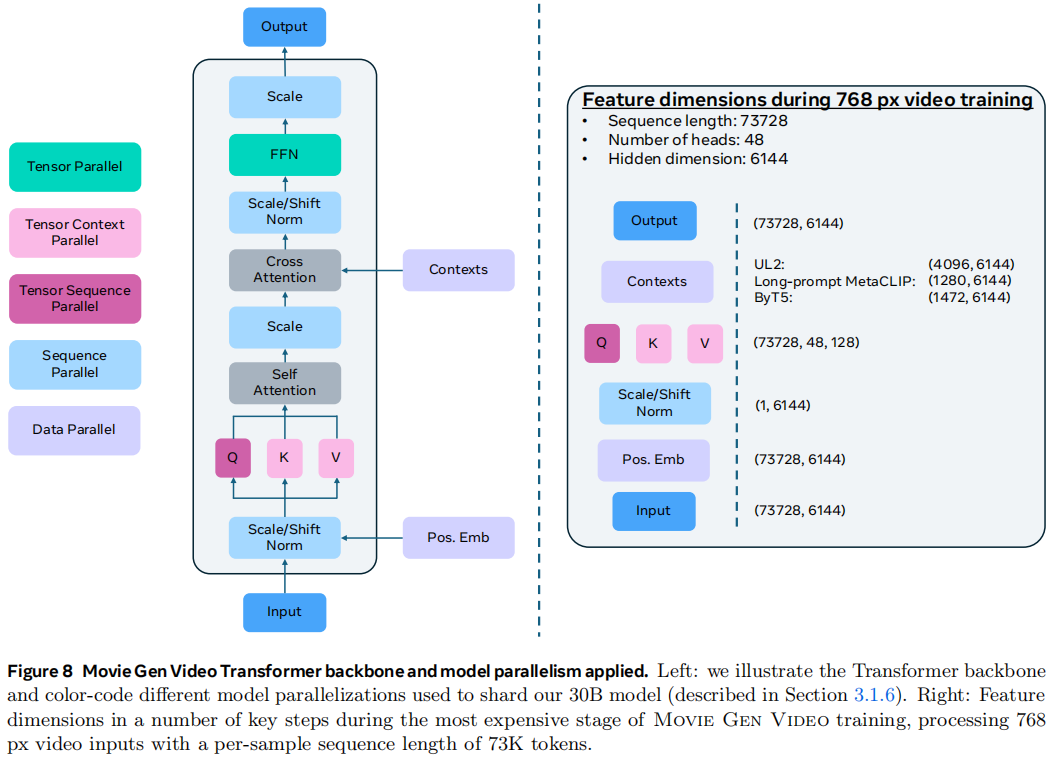
依然是先做patchfiy,用3D conv把latent embedding打成一系列的token然后铺平到1D序列
使用factorized learnable positional embedding来使得可以做任意分辨率和时长的transformer的输入,思路是把不同维度的dimension映射成一个[0, max_len]的mapping,对视频来说长 H,宽 W 和时间 T 都会有一个最大值,任意的值都会在这个mapping区间做一个插值。然后将这种positional embedding加到transformer当中每一个layer里面,这样能减少视频的失真
骨架网络用的LLaMa3,主要做了三个改动:
- text embedding给每一层加上了cross attention,因为不同的文本编码器关注的内容不一样,因此不是把embedding相加而是concat起来
- 使用了adaptive layer norm blocks,这样能更好的把时间步信息加进来
- 用的bi-directional attention而不是causal attention
模型的骨架设计尽量和LLaMa3一致,这样把语言模型的经验迁移过来
3.1.4 Rich Text Embeddings and Visual-text Generation
用了UL2、ByT5和Long-prompt MetaCLIP做text encoder
- MetaCLIP有一个visual tower和text tower,对视觉prompt任务很友好,更加全局
- character-level ByT5捕获局部的文本信息
- UL2也是提供prompt-level的embedding
3.2 Pre-training
3.2.1 Pre-training Data
预训练数据在O(100)M的视频-文本对,O(1)B的图像-文本对,数据设计人、自然、动物等比较多样化的
经过clip-prompt之后每个视频大概在4秒-16秒,尽可能每个视频描述的一个物体或一个概念,对模型训练比较友好,平均每个短视频有100个字的摘要
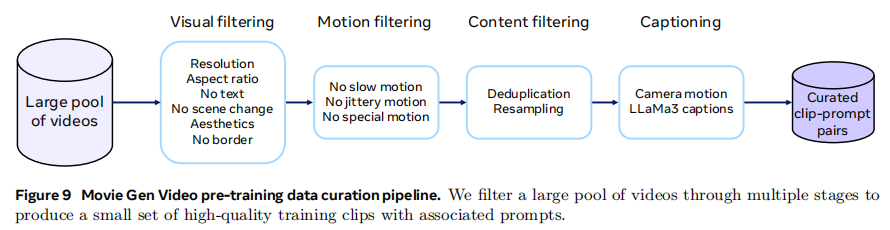
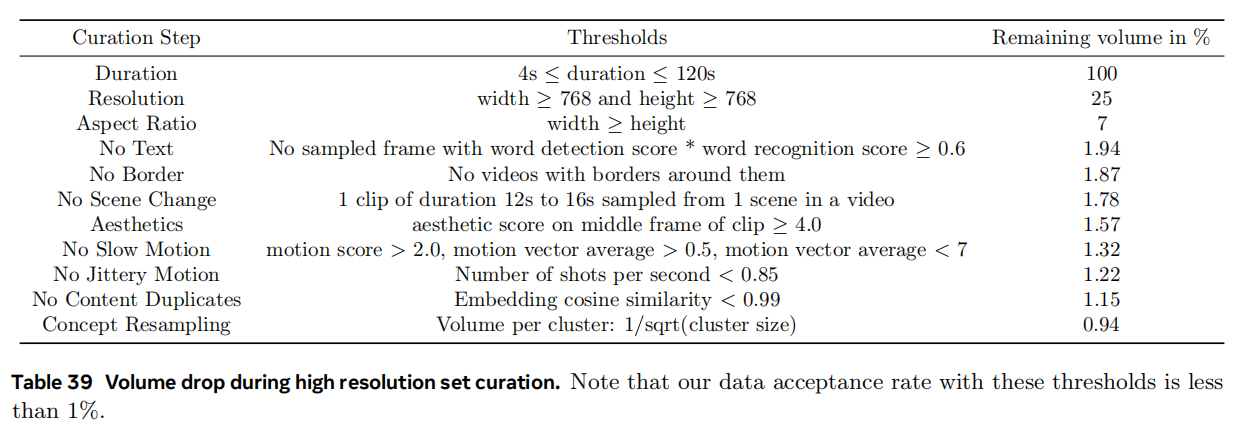
主要用了6个filter来处理,很多是使用model的方法来过滤,而不仅仅是粗筛
- Visual filtering. 一般来说横屏视频更好,竖屏的短视频存在动作不稳定、艺术性更差、质量更差等问题,同时还需要除去一些读书之类的视频,不要有多个场景的切换(scene boundary detection),还有美观上的filter,去除视频的黑边框等等
- Motion filtering. 用一个内部的静态model去检测没有motion的视频;用VMAF motion score和motion vector来给动作打分筛选“合理”的视频;对于有jittery camera movements的用shot boundary detection来判断,假设一个1秒的视频被切割成数份,那说明存在视频抖动的情况;去除特殊的视频比如幻灯片
- Content filtering. 抽embedding再做clsutering,从每个cluster根据inverse square root of the cluster size去抽取确保训练不会bias
- Captioning. 给video clip,用LLaMa3-Video针对注释的任务fine-tune,然后对所有的视频数据做注释,8B(70%)和70B(30%)混合做(inference价格高昂以及需要一些diverse)。还预测了镜头的16种变换,比如zoom-in,zoom-out,可以判断常见的camera motion以实现更好的camera control
- Multi-stage data curation. 对于filter来说,从简单到困难分为了3个stage,从低清转高清,80%横屏,20%竖屏,其中60%有人
3.2.2 Training
30B的模型采用多阶段训练,包括三个步骤:
- 先用text-to-image(T2I)做warm up,再做text-to-video(T2V)
- 从低清的256p到高清的768p
- 洗数据集、调参训练
训练单方见表3,会保持一个完全没见过的验证集,而且很多时候还是看human evaluation
3.3 Finetuning
为了提升模型最终效果,还需要做fine-tuning,这里的数据集都是靠人构建的
- Finetuning Video Data. 高质量的数据集要有good motion、更真实、更美观、diverse等等。为了找到这些数据集,有四步顺序执行:
- 对美观和动作上设置了更严格的阈值,还用目标检测的模型把特别小的物体给去掉了,这一步大概保留了小几百万的视频,但是概念分布是很不均匀的
- 然后用人工筛选出高质量的数据集,作为种子视频用text和video的k-nn来筛选概念上相近的数据
- 人工筛选出好看的,适合训练的样本,主要原因还是高质量的微调数据还是无法通过自动程序很好的抓取出来,比如很多是人的主观感受,比如角度、饱和度、色彩、光感等。还要人工挑选出一个视频中质量最高的片段
- 模型先生成视频注释的底稿,然后再修改,生成包括镜头控制、物体、背景信息、动作信息、光影信息等
- 最后生成的数据集50%在16s,剩下的在10.6s~16s之间
- Model Averaging. 因为数据集的配比很关键,很难找到一套通用的超参数把所有的场景都做得很好,所以多个checkpoint通过平均得到最终的模型
3.6 Results
3.6.1 Comparisons to Prior Work
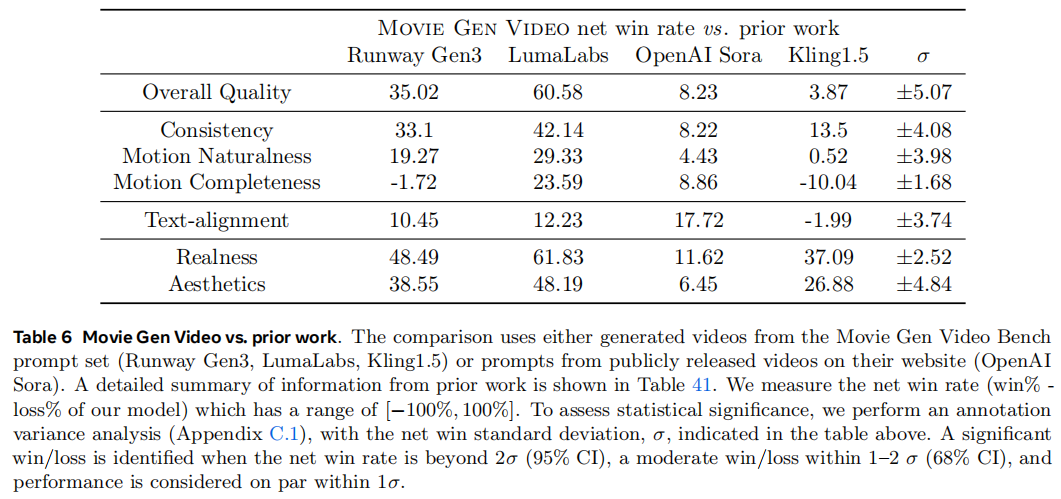
和一些闭源、开源的模型比较,指标是net win rate,模型对比赢的比例
3.6.4 TAE Ablations
使用的指标有reconstructed peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and Fréchet Inception distance (FID)
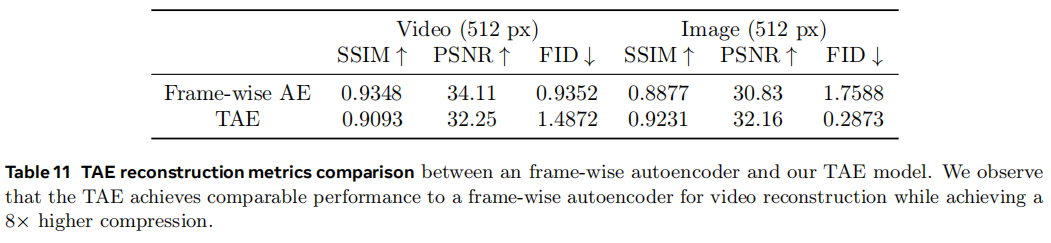
从表11来看,在frame上做了压缩性能是会变差
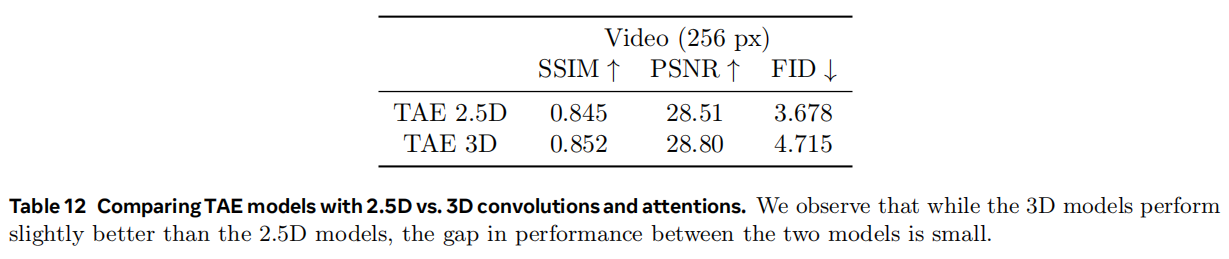
从表12可以看到TAE 3D还是好于TAE 2.5D的,但是性能上没有非常明显的提升,反之2.5D的效率会好很多

