
论文地址:Evaluating Large Language Models in Scientific Discovery
SDE-harness:AI评估8个领域科学问题
Abstract
这篇论文的摘要简明扼要地指出了当前大语言模型(LLM)在科学评估中的局限性,并正式提出了一个新的评估框架——科学发现评估(Scientific Discovery Evaluation, SDE)。
1. 现有基准的局限性 尽管 LLM 正越来越多地应用于科学研究,但目前主流的科学基准测试主要考察的是脱离语境的知识(decontextualized knowledge)。这些测试忽略了驱动科学发现的真正核心能力:迭代推理、假设生成和观测解释 。
2. SDE 框架的构建 为了解决上述问题,作者引入了一个基于场景(scenario-grounded)的基准测试,涵盖生物、化学、材料和物理四大领域。该框架由领域专家定义具有真实研究价值的项目,并将这些项目分解为模块化的研究场景,进而从中采样经过验证的问题 。
3. 双层评估机制 SDE 框架在两个层级上对模型进行评估:
- 问题层级(Question-level):评估模型在与具体研究场景紧密相关的问题上的准确性 。
- 项目层级(Project-level):要求模型模拟端到端的科研过程,包括提出可测试的假设、设计模拟或实验,以及解释结果 。
4. 关键发现与结论 通过对最先进的 LLM 进行评估,研究揭示了以下重要现象:
- 性能落差:模型在 SDE 上的表现普遍低于通用的科学问答基准 。
- 收益递减:扩大模型规模和增强推理能力带来的性能提升呈现收益递减趋势 。
- 共性缺陷:不同提供商的顶尖模型表现出系统性的共同弱点 。
- 缺乏通用“超级智能”:模型在不同研究场景中的表现差异巨大,导致在不同项目中“最佳模型”的人选不断变化,说明目前的 LLM 距离通用的科学“超级智能”尚远 。
- 意外发现的潜力:尽管基础场景得分可能较低,LLM 仍能在多种科学发现项目中展现潜力,突显了引导式探索和意外发现(serendipity)在科学研究中的作用 。
最终,SDE 框架旨在提供一个可复现的、以发现为导向的评估基准,为推动 LLM 向科学发现方向发展指明路径 。
Introduction
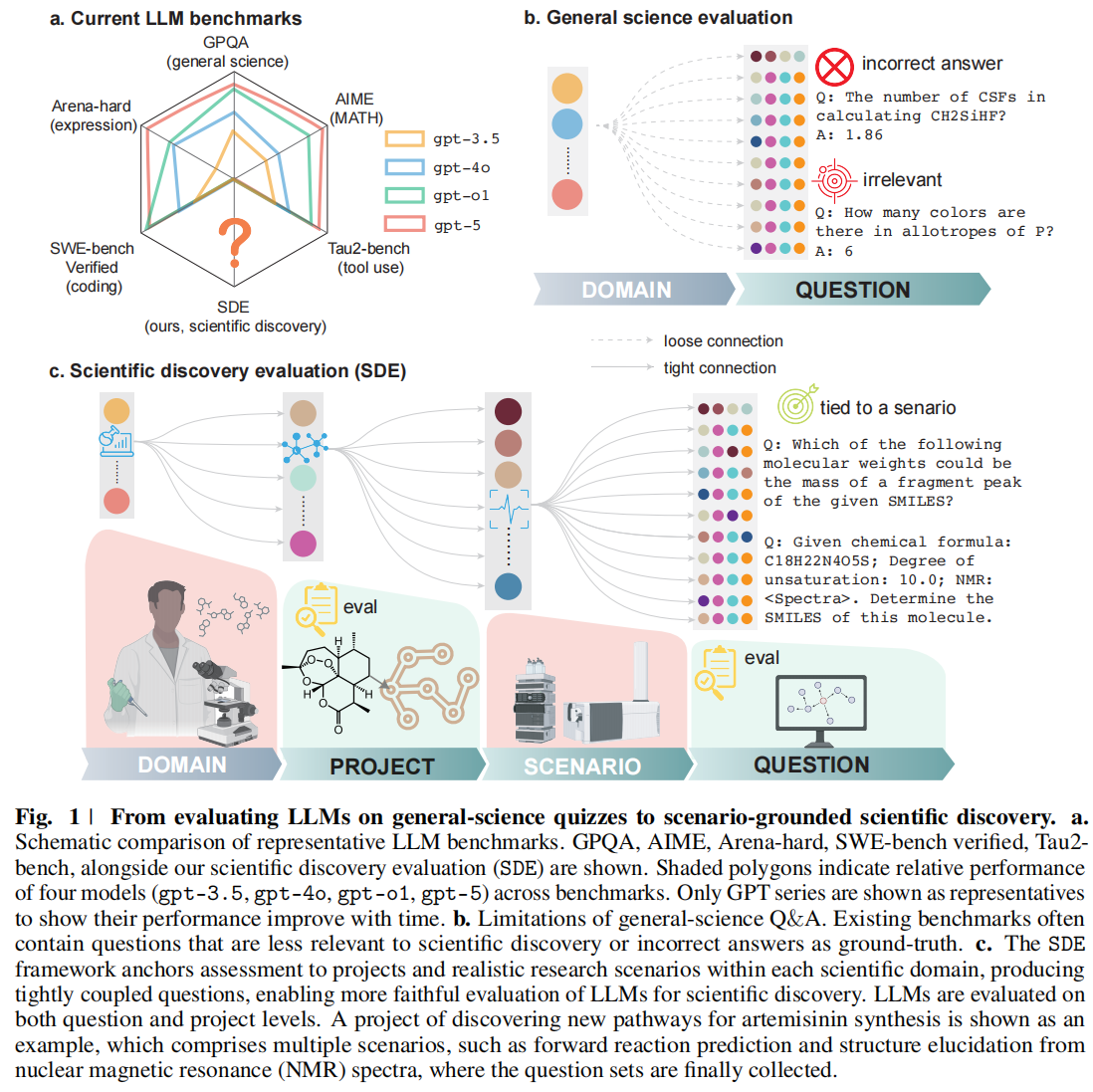
1. 现状:LLM 正加速融入科学发现的全流程
引言首先肯定了 LLM 在科学领域的进展。LLM 正开始加速科学发现的核心阶段,涵盖了从文献筛选、假设生成到计算模拟、代码合成,甚至是自主实验 。
- 角色演变:LLM 已经从最初的结构-属性预测和简单问答的替代品,演变为具备推理能力(得益于强化学习和推理时的计算 scaling)的工具,能够提供直觉和洞察 。
- 成功案例:文中列举了 ChemCrow、自主“合作科学家(co-scientists)”以及用于纳米抗体设计的 Virtual Lab 等例子。这些系统通过将语言推理与领域工具、实验室自动化甚至具身系统(如 LabOS)结合,表明 LLM 已经可以在“人机回环(human-in-the-loop)”的科学发现中辅助科学家 。
2. 痛点:评估滞后于应用现实
- 对比成熟领域(Fig. 1a):在代码(如 SWE-bench Verified)、数学(如 AIME)和工具使用等领域,基准测试已相对成熟,具备明确的“标准答案(ground truth)”和较强的预测有效性(如图 1a 所示,各模型能力在雷达图中清晰分布)。
- 科学评估的缺陷(Fig. 1b):现有的主流科学基准(如 GPQA, ScienceQA)主要由去语境化(decontextualized)的问答组成 。如图 1b 所示,这些题目往往与具体科研领域联系松散(loose connection),且容易包含噪声或无关信息。
- 核心论点:精通这些静态问题并不代表做好了科学发现的准备,正如“在课程中拿全 A 并不代表能成为一名伟大的研究员” 。真正的评估必须衡量模型对研究背景(context of research)的理解、在证据不完美下的推理能力以及迭代修正假设的能力。
3. 解决方案:SDE (Scientific Discovery Evaluation) 框架
为了解决上述痛点,作者提出了 SDE 框架,这是一个扎根于真实世界研究场景的系统性评估 。
- 紧密连接(Fig. 1c):与传统基准不同,SDE 建立了领域(Domain)$\rightarrow$ 项目(Project)$\rightarrow$ 场景(Scenario)$\rightarrow$ 问题(Question)的层级结构(如图 1c 所示),确保每个问题都与真实的科研项目紧密耦合(tight connection)。
- 覆盖领域:涵盖生物、化学、材料和物理四大领域。
- 构建逻辑:专家定义真正的研究项目,将其分解为模块化的、有科学依据的“研究场景”,并在场景内构建经过审查的问题。
4. 评估方法:从“做题”到“做科研”
SDE 引入了双层评估机制,旨在揭示 LLM 的真实能力 :
- 问题层级(Question-level):评估模型在特定场景下的答题准确率 。
- 项目层级(Project-level):这是关键创新。模型被置于科学发现的闭环中,必须自主提出可测试的假设、运行模拟或实验、解释结果并修正假设 。例如图 1c 展示的青蒿素(artemisinin)合成路径发现项目,就包含了正向反应预测和 NMR 谱图结构推断等多个场景。
通过对随时间发布的最先进(SOTA)模型进行纵向、细粒度的评估,SDE 揭示了当前模型在哪里成功、在哪里失败以及为什么失败 。分析结果指出了未来的发展路径:包括针对问题表述(problem formulation)的定向训练、多样化数据源、在训练中融入计算工具的使用,以及设计针对科学推理的强化学习策略 。
Results
Question-level evaluations
Performance gap in quiz- and discovery-type questions
1. 超越传统基准的构建流程
为了超越那些问题有时是“机会主义式拼凑(assembled opportunistically)”的传统科学问答(Q&A)基准,SDE 中的问题采用了完全不同的收集流程(如图 1c 所示)。
- 专家定义场景:在每个领域(生物、化学、材料、物理),由多成员组成的专家小组定义了大约 10 个常见的研究场景(Research Scenarios)。这些场景是 LLM 可能在专家正在进行的项目中切实提供帮助的地方 。
- 场景的跨度:这些场景覆盖了广泛的范围,从人类专家擅长的任务(例如:根据具体的实验观测做出决策),到如果不借助工具人类专家也无法处理的任务(例如:仅凭结构推断过渡金属配合物的氧化态和自旋态)。
2. 混合生成策略 (Hybrid Generation Strategy)
为了构建高质量的问题,研究团队采用了半自动生成与人工起草相结合的策略:
- 半自动生成 (Semi-automatically):在可行的情况下,问题是通过从现有的基准数据集或开放数据集(open datasets)中采样并利用模板生成的 。
- 案例:以“从 NMR(核磁共振)光谱映射到分子结构”为例,这类问题就是通过模板化转换结构化条目生成的 。
- 专家人工起草 (Drafted Manually):对于其他情况,特别是涉及实验相关(experiment-related)的场景,问题是由领域专家手动起草的 。
3. 严格的质量控制 (Quality Control)
- 专家评审:每一个问题都经过了专家小组的评审(panel review)。
- 纳入标准:只有在对问题的有效性(validity)和正确性(correctness)达成共识后,该问题才会被纳入基准。最终,SDE 基准共包含了 1,125 个高质量问题 。
4. 设计意义:拒绝“去语境化”
这种设计将每一个问题都绑定到一个具体的研究场景中,确保了回答的正确性反映的是在实际科学发现项目(practical scientific discovery project)上的进展,而不仅仅是回答了“去语境化的琐事(decontextualized trivia)”。这也允许研究人员在相同的粒度水平上对不同的 LLM 进行比较 。
5. 评估目标与模型选择
为了理解流行的编码、数学和表达基准的性能如何转化为科学发现能力,该研究评估了来自不同提供商(如 OpenAI, Anthropic, Grok, 和 DeepSeek)的顶尖模型。评估使用了 lm-evaluation-harness 框架的改编版本,以支持灵活的任务类型评估 。
6. 揭示性能差距 (The Performance Gap)
为了定位结果,研究者将模型在 SDE 发现型问题上的表现与广泛使用的通用科学 Q&A 基准进行了对比。
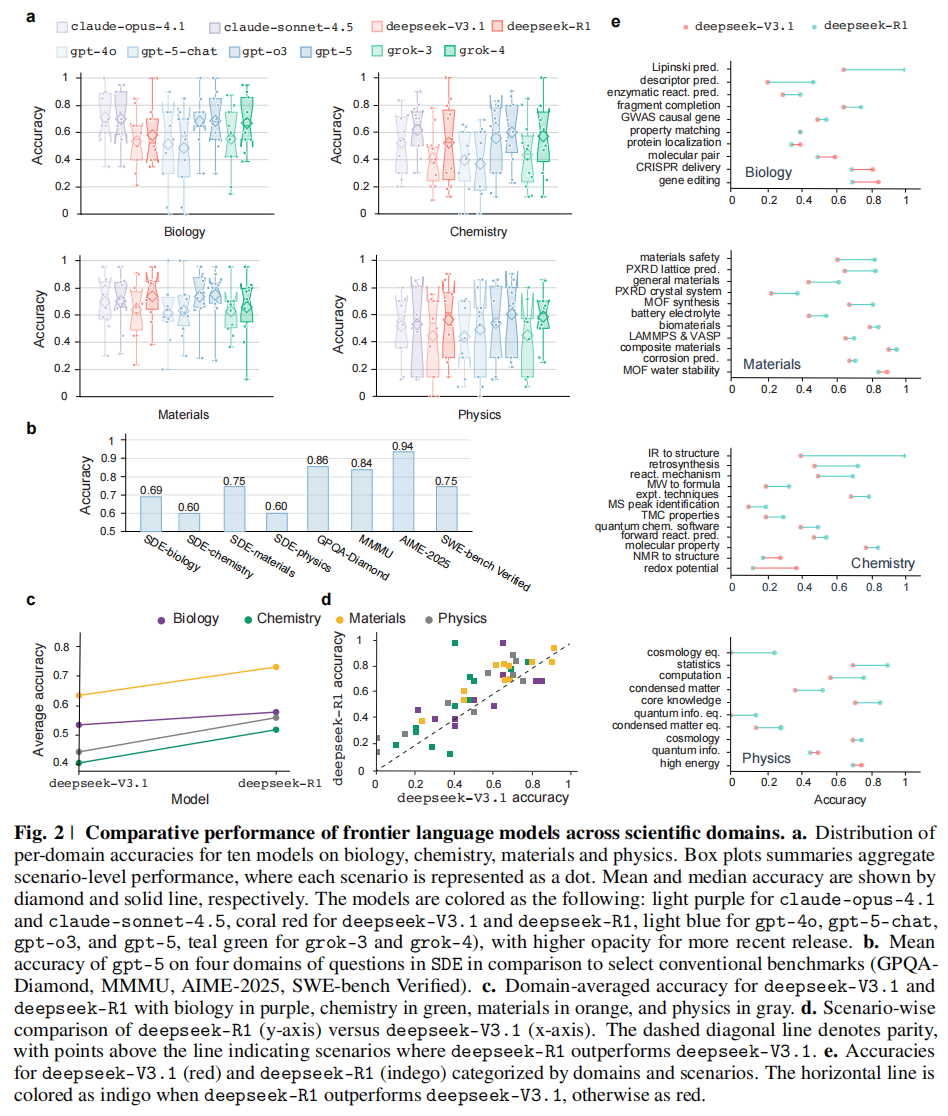
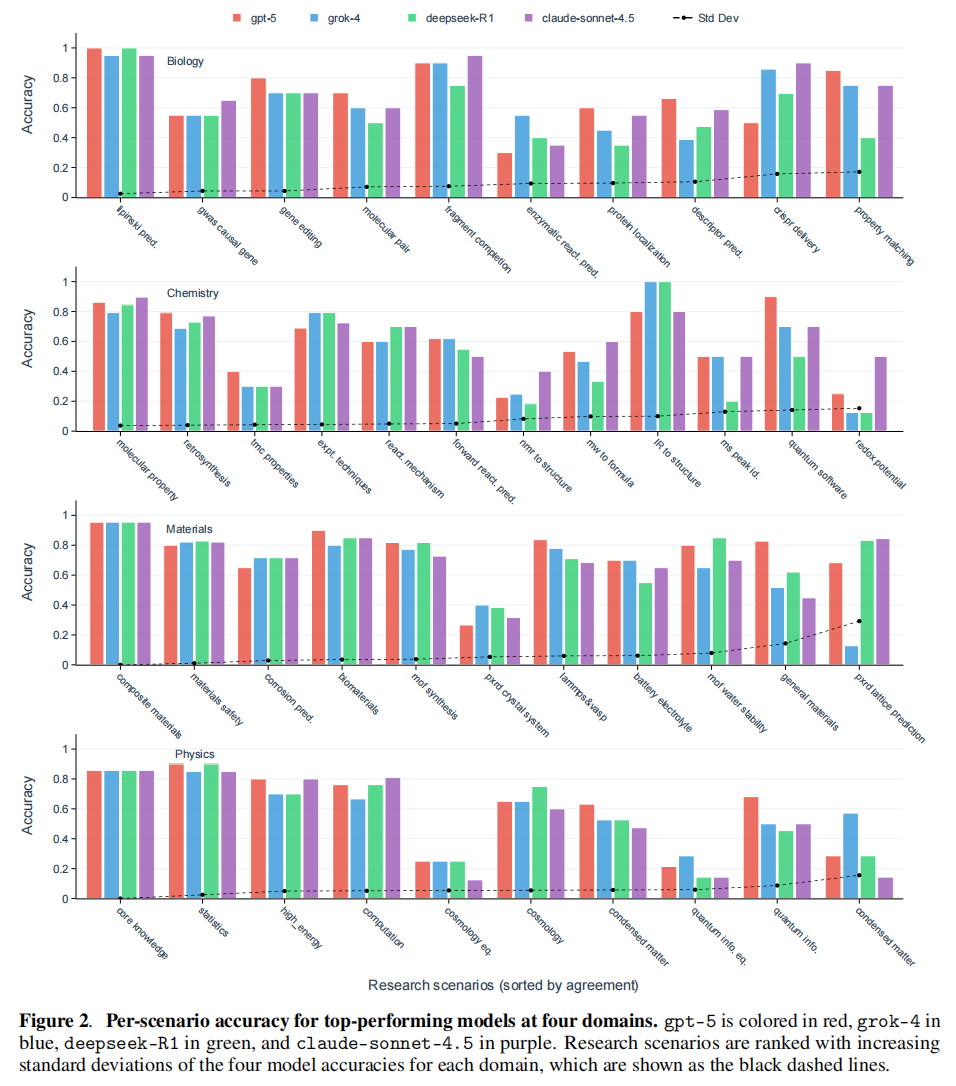
- SDE 得分:最先进的模型在生物学得分 0.71 (Claude-4.1-opus),化学 0.60 (Claude-4.5-sonnet),材料学 0.75 (GPT-5),物理学 0.60 (GPT-5) ,图2a。
- 通用基准得分:相比之下,同类模型在 MMMU-Pro 上得分可达 0.84,在 GPQA-Diamond 上可达 0.86 (GPT-5),图2b。
- 结论:这说明了在去语境化的问答(decontextualized Q&A)与基于场景的科学发现问题之间,存在一致的性能鸿沟(Performance Gap)。这意味着高分的考试成绩并不等同于具备了解决实际科研问题的能力。
Reasoning and scaling plateau
在既有的代码和数学基准测试中,SOTA 模型的性能通常随着新版本的发布而提升,其中推理能力是推动这些收益的主要因素,这在科学发现中同样重要 。
1. 推理带来的显著收益 (Clear Benefits of Reasoning)
在其他条件相似的模型正面交锋中,具备显式测试时推理(test-time reasoning)能力的变体模型,在 SDE 问题上的表现始终优于不具备该能力的对应模型。
- DeepSeek 的案例:这一效应在 DeepSeek-R1 与 DeepSeek-V3.1 的对比中体现得最为明显(两者共享相同的基础模型)。如图 Fig. 2c 所示,DeepSeek-R1 在四个领域(生物、化学、材料、物理)的平均准确率均高于 DeepSeek-V3.1 。
- 跨领域的一致性:这种提升跨越了绝大多数的科研场景。图 Fig. 2d 展示了两个模型的场景级对比,绝大多数点位于对角线(parity line)上方,表明与多步推导和证据整合相对应的推理能力的提升,能够直接转化为发现导向场景中更高的准确率 。
- 具体实例:一个显著的例子是让 LLM 判断一个有机分子是否符合 Lipinski 五规则(Lipinski’s rule of five,药物候选分子口服生物利用度的重要指南)。如图 Fig. 2e 所示,在这个需要大量推理的任务中,DeepSeek 模型在开启推理能力后,准确率从 0.65 飙升至 1.00 。
2. 推理收益的饱和 (Saturation of Reasoning Gains)
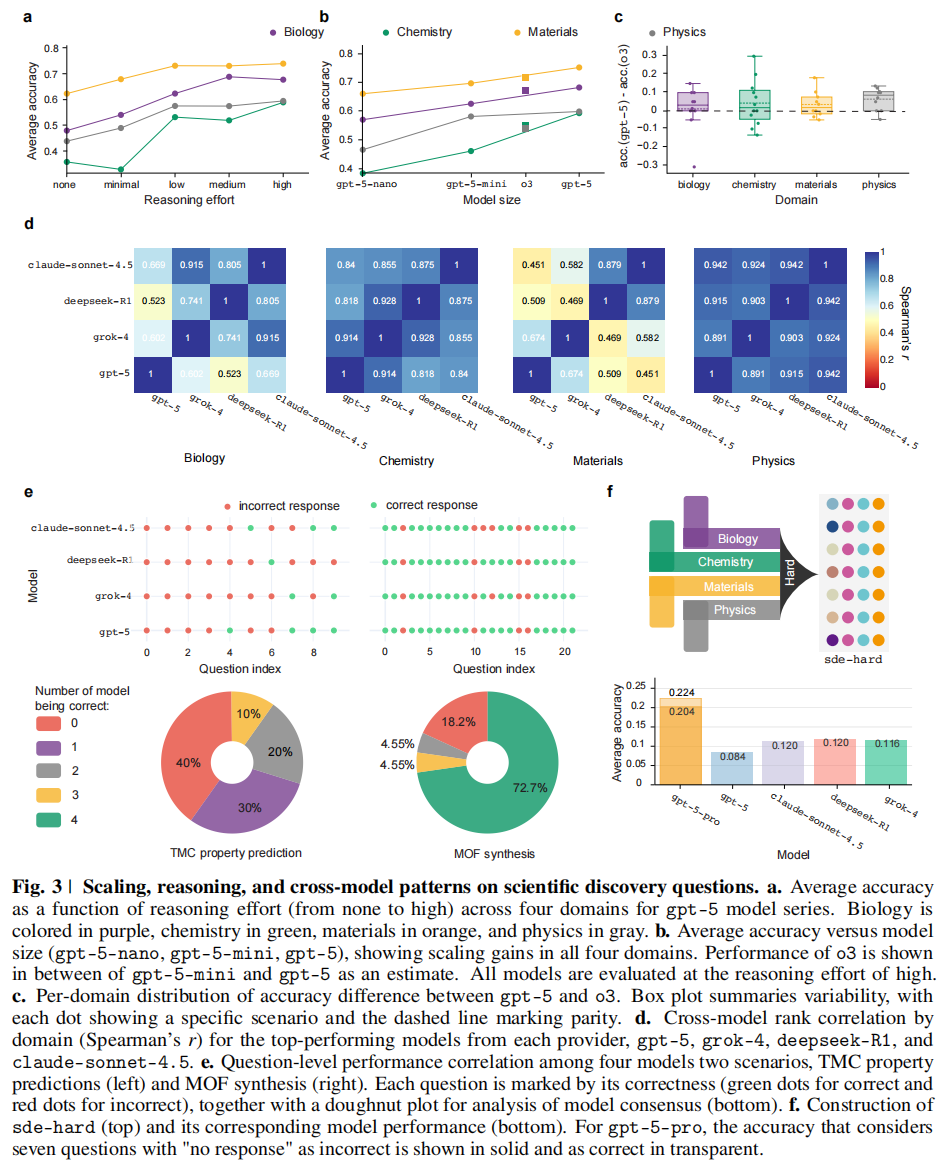
尽管推理的好处显而易见,但作者在追踪 gpt-5 不同程度的推理努力(reasoning efforts)时发现,SDE 基准上的整体性能开始趋于饱和。
- 收益递减:即使相应的模型在代码或数学上刷新了记录,其在科学发现上的收益也变得温和,甚至往往在统计误差范围内。这一趋势在图 Fig. 3a 中清晰可见,随着推理努力从“无(none)”增加到“高(high)”,曲线逐渐平缓 。
- 具体数据对比:在“中等(medium)”和“高(high)”推理努力之间,准确率几乎没有提升 :
- 生物:0.70 vs 0.69
- 化学:0.53 vs 0.60
- 材料:0.74 vs 0.75
- 物理:0.58 vs 0.60
- 结论:这表明,以科学发现为目的,单纯增加测试时计算(test-time compute)这一主流技术路线的收益正在出现边际效应递减(参考 Supplementary Fig. 7)。
3. 规模效应的放缓 (Scaling Plateau)
除了推理,扩大模型规模(Scaling up)通常被认为是 LLM 成功的巨大贡献因素 。
- 单调提升:作者确实观察到,随着 gpt-5 从 nano 扩展到 mini 再到其默认的 large 尺寸,模型准确率呈现单调提升,如图 Fig. 3b 所示 。
- 增长放缓:然而,规模效应在过去一年中似乎也放慢了脚步。如图 Fig. 3c 所示,gpt-5 相比于 o3 的性能提升非常微弱(marginal),甚至在 8 个场景中,gpt-5 的表现显著更差(准确率下降超过 0.075)。
- 基础模型收敛:类似地,当剥离推理因素后,从 gpt-4o 到 gpt-5 的性能提升也可以忽略不计。这表明在过去 18 个月中,预训练基础模型(pretrained base foundation LLMs)在发现型任务上的表现似乎已经收敛(converged) 。
4. 核心启示
推理和规模分析的意义并不在于进步已经停滞,而是揭示了:科学发现所强调的能力不同于通用的科学问答。它更侧重于:问题表述(Problem formulation),假设修正(Hypothesis refinement),对不完美证据的解释(Interpretation of imperfect evidence) 。
Shared failure modes among top-performing LLMs
1. 跨模型的高度相关性 (High Correlation Across Models)
- 现象:当对比来自不同提供商的顶尖模型(gpt-5, grok-4, deepseek-R1, claude-sonnet-4.5)时,研究发现它们的准确率分布高度相关 。这意味着这些模型往往在相同的场景下表现出色,又在相同的场景下遭遇失败 Fig. 3d 和 Supplementary Fig. 5。
- 数据支持:这种相关性在化学和物理领域最为突出。在这些领域中,上述四个顶尖模型之间的所有两两 Spearman 相关系数(Spearman’s r)和 Pearson 相关系数(Pearson’s r)均大于 0.8 。
2. 错误趋同:在相同的难题上犯同样的错 (Converging on the Same Incorrect Answers)
- 共识性失败:顶尖模型经常在最困难的问题上收敛到完全相同的错误答案,即使它们的总体准确率可能有所不同 Fig. 3e 和 Supplementary Fig. 6。
- 具体案例:文中举了 MOF(金属有机框架)合成 问题的例子。尽管模型在这一领域的总体表现相对较高,但在总共 22 个问题中,有 4 个问题是这四个顶尖模型都犯了同样错误的 。
- 原因分析:这种错误的对齐表明,前沿 LLMs 共享着共同的优势以及共同的系统性弱点。这很可能继承自相似的预训练数据分布和训练目标,而不是源于它们各自独特的架构或实现细节 。
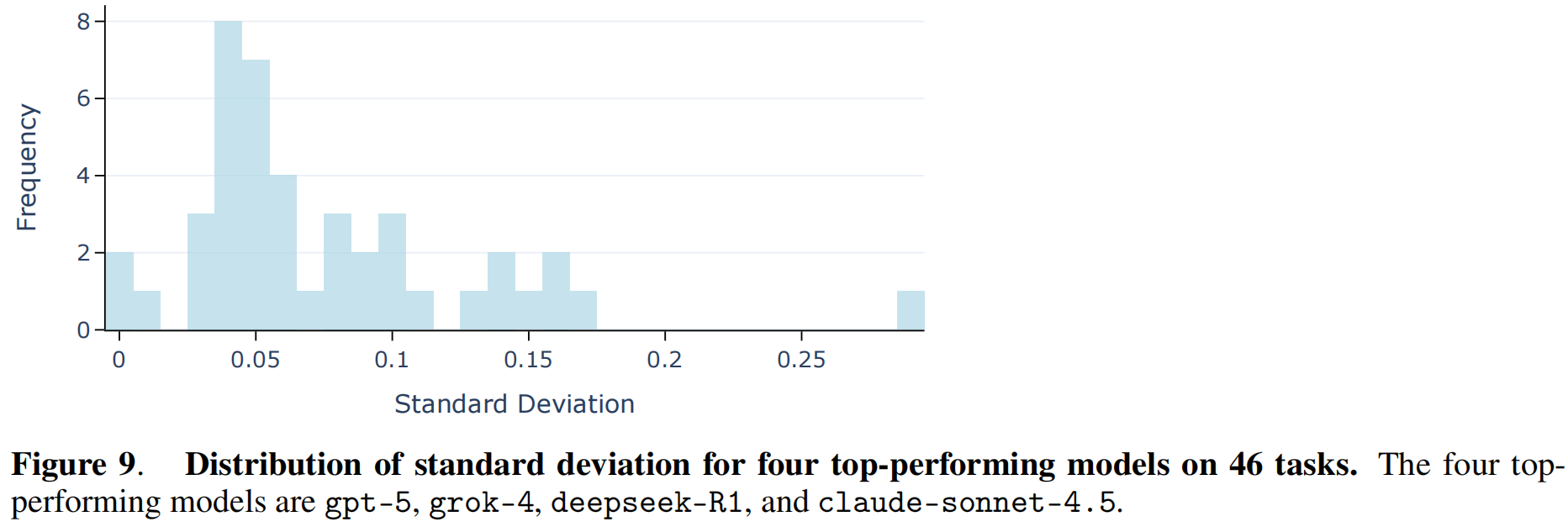
3. 实践启示:集成策略的局限性 (Limitation of Ensemble Strategies)
- 多数投票无效:由于模型倾向于犯相同的错误,简单的集成策略(如跨提供商的多数投票 majority voting)对于那些当前 LLM 固有的难题可能效果有限 。因为当所有“专家”都给出相同的错误建议时,投票无法修正结果 Supplementary Fig. 2 和 Fig. 9 。
- SDE 设计的价值:SDE 这种基于场景的设计让这些相关性变得可见且可复现,不仅揭示了模型在哪里成功,更细粒度地暴露了它们在发现型任务中在哪里失败以及为什么失败 。
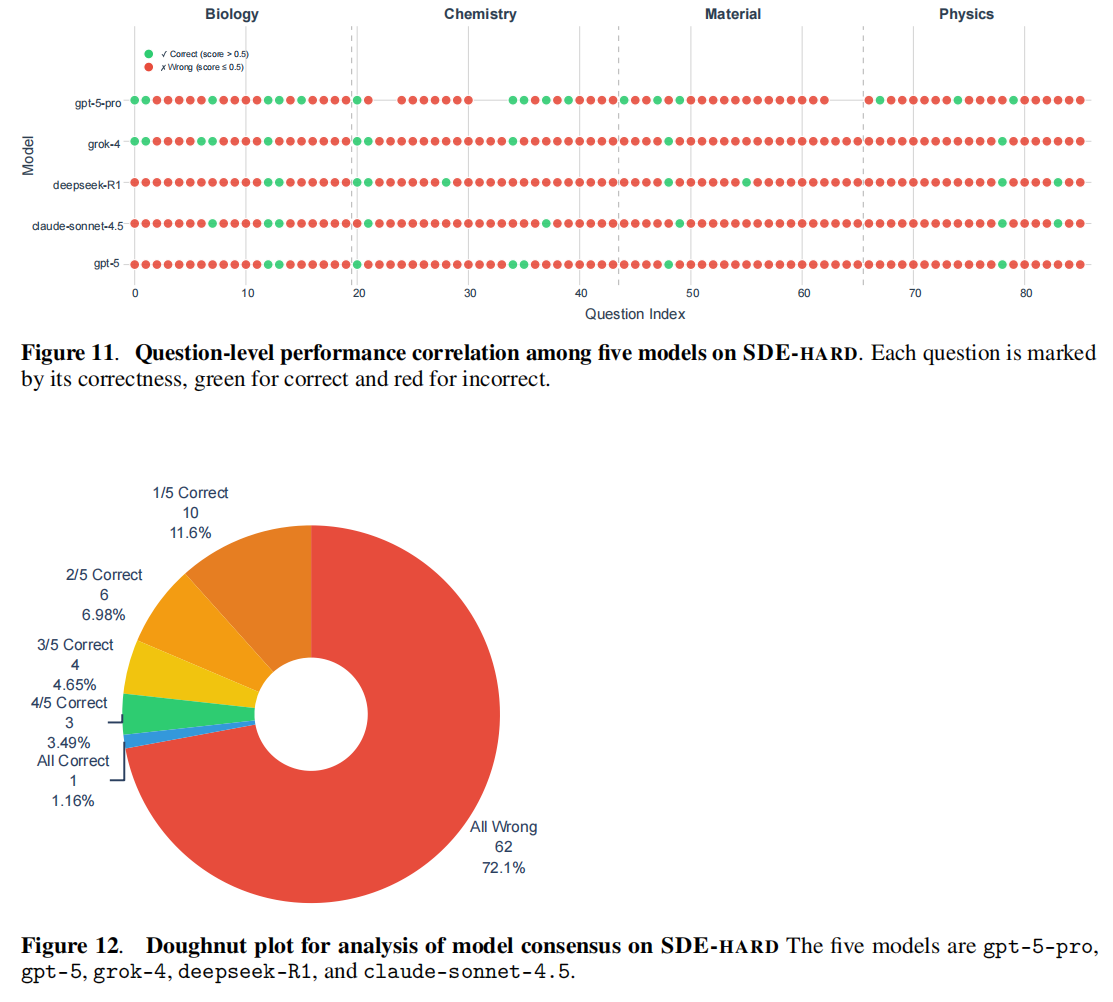
4. SDE-hard:最难的科学发现问题 (SDE-hard Subset)
- 数据集构建:鉴于这种“共识性失败”行为,作者进一步筛选出了 86 个最难的问题(每个研究场景选出 2 个顶尖模型出错最多的问题),组成了一个名为 SDE-hard 的子集 Supplementary Fig. 11 和 Fig. 12 。
- 模型表现:所有常规 LLMs 在这些最难的科学发现问题上的得分均低于 0.12 。
- GPT-5-pro 的突破:
- 例外表现:gpt-5-pro 在这部分表现出了显著优势。尽管其推理成本极高(12倍),但它在 9 个其他所有模型都答错的问题上给出了正确回答 Fig. 3f (下) 。
- 意义:这表明 GPT-5-pro 在需要扩展推理(extended reasoning)的极难问题上具有竞争优势,而这正是科学发现的特征 。不过,即便是它,在这个子集上的准确率仍有很大提升空间,使 SDE-hard 成为未来高推理成本模型极佳的测试场 。
Project-level evaluations
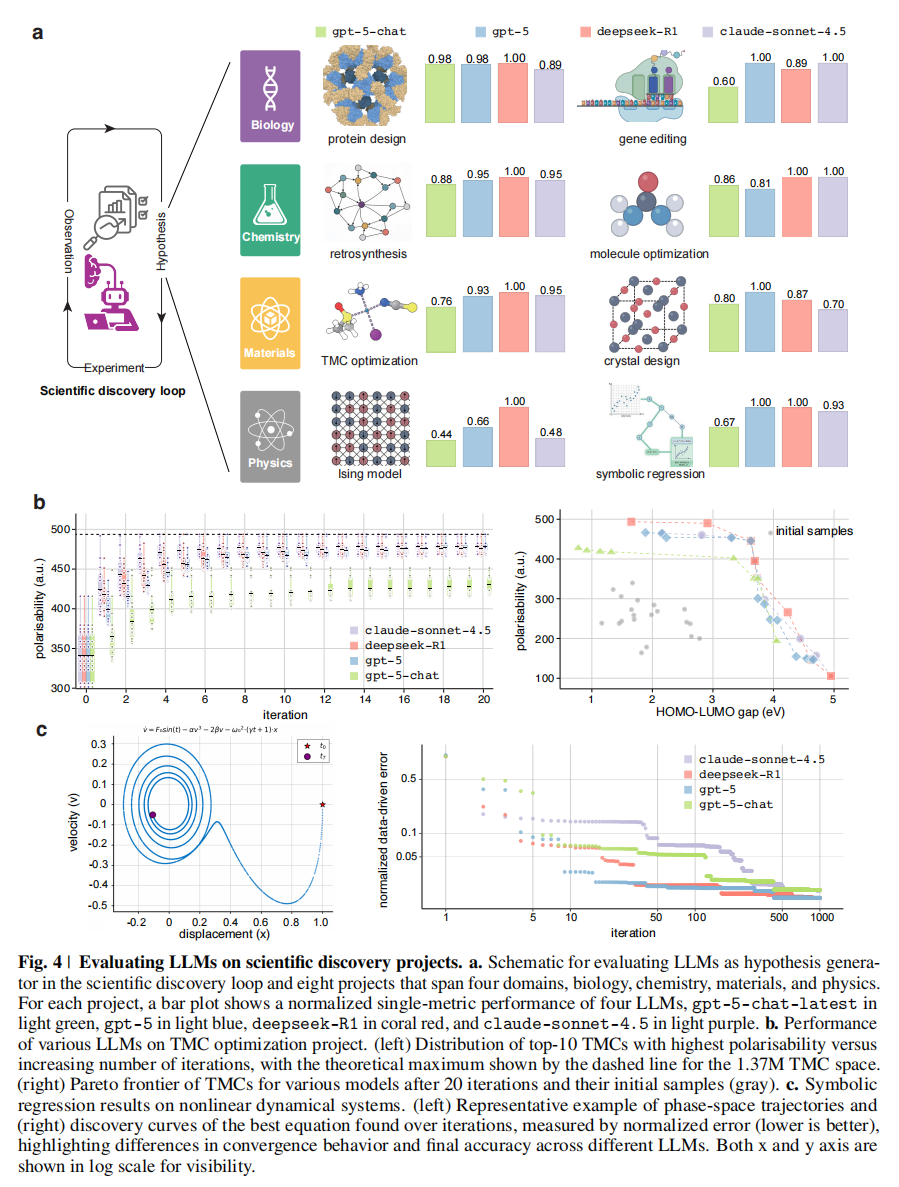
Establishing LLM evaluation on the scientific discovery loop
1. 评估范式的转变:从单轮问答到迭代循环
传统的问答(Q&A)基准通常通过单轮交互来评估模型,针对静态查询的一对一回答进行评分 。然而,真正的科学发现是通过假设提出、测试、解释和修正的迭代循环来推进的 。为了反映这一过程,作者引入了 sde-harness,这是一个模块化的框架,正式确立了假设、实验和观测的闭环发现过程(Fig. 4a)。在这个框架中,LLM 取代了人类研究者,担任假设生成器的角色 。
2. 评估核心:捕捉静态测试无法衡量的能力
这一框架超越了单一问题的准确率评估,实现了项目层级的考核。它要求模型制定可测试的假设,执行分析或模拟,并解释结果以逼近端到端的发现工作流 。因此,sde-harness 能够分离出静态 Q&A 测试无法捕捉的能力,例如在多个评估轮次中保持状态(maintaining state)、整合中间证据,以及战略性地决定何时分支或放弃某条探索路径的能力 。
3. 项目构成:八大项目与三大要素
研究团队实例化了涵盖生物、化学、材料和物理的八个项目,每个项目都与 SDE 问答基准中的特定研究场景相对应 。每个项目都定义了三个关键要素:
- (i) 假设空间:例如逆合成路线、具有目标电子特性的金属-配体复合物,或数学关系的符号表达式 ;
- (ii) 计算 Oracle 或模拟器:用于将假设映射到观测结果 ;
- (iii) 选择规则:用于在迭代过程中传播有希望的假设 。
4. 模拟真实的发现过程
具体而言,sde-harness 编排了迭代优化过程,以模仿真实的科学发现循环 。这种透明的更新机制揭示了 LLM 如何随着时间的推移修正其假设,从而将迭代推理(iterative reasoning)与单纯的一次性生成(one-shot generation)区分开来 。
Serendipity in LLM-driven optimizations
1. 结构化数据项目中的显著收益
研究发现,在那些拥有大量结构化开源数据和编码知识的项目中,集成 LLM 带来的收益最为显著 。这些项目包括:蛋白质设计,过渡金属配合物(TMC)优化,有机分子优化,晶体设计,符号回归
2. 案例分析一:符号回归 (Symbolic Regression)
在这个物理学项目中,模型需要从数据中迭代发现非线性动力系统的控制方程。这要求模型不仅能对假设空间进行结构化探索,还要能逐步优化符号形式 。
- 推理模型的动态优势:具备推理能力的模型展现了更有效的发现动力学(Fig. 4c)。特别是 deepseek-R1 和 gpt-5,它们比 claude-sonnet-4.5 和 gpt-5-chat-latest 收敛得更快,且能达到更低的最终误差 。
- 持续优化能力:这些模型能在早期迅速降低误差,并在数百次迭代中持续改进候选方程,表明其在符号假设空间中实现了更可靠的“探索-利用(exploration-exploitation)”平衡 。
- 超越传统基准:与广泛使用的 SOTA 基准 PySR 相比,LLM 方法表现出了显著的性能差距。PySR 的准确率大幅降低,且归一化均方误差(NMSE)显著更高,尤其是在分布外(OOD)区域 。
- 成功原因:这一结果突显了 LLM 引导发现的关键优势——能够基于知识提出、修改和重组符号结构,以一种全局知情的方式进行搜索,而不是像传统方法那样仅依赖对算子的局部搜索 。
3. 案例分析二:过渡金属配合物 (TMC) 优化
在材料科学领域,模型需要在巨大的化学空间中寻找具有目标属性的分子。
- 极速收敛:当任务是识别具有最大极化率(polarisability)的候选者时,gpt-5、deepseek-R1 和 claude-sonnet-4.5 都展现了快速收敛的能力。它们能在 137 万个 TMC 的搜索空间中,仅通过不到 10 次迭代(推荐少于 100 个分子)就定位到最优解(Fig. 4b) 。
- 值得注意的是,claude-sonnet-4.5 在不同的初始化集合中表现出了优越的收敛速度和鲁棒性 。
- 帕累托前沿探索 (Pareto Frontier):在探索由极化率和 HOMO-LUMO 能隙定义的帕累托前沿时:
- deepseek-R1 产生了最广泛且平衡的分布,有效地覆盖了“小能隙/高极化率”和“大能隙/低极化率”两个区域(Fig. 4b) 。
- 相比之下,claude-sonnet-4.5 对初始种群非常敏感,其探索主要局限在“大能隙/高极化率”区域 。
- 推理的重要性:在上述两个场景中,非推理模型 gpt-5-chat-latest 的表现均优于其增强了推理能力的版本,这强调了多步推导和推理在 TMC 优化中的关键作用 。
Connecting question- and project-level performance.
Performance on scenarios does not always translate to projects.
SDE 框架的一个核心特征是它通过定义明确的研究场景,连接了问题层级和项目层级的评估,从而能够直接分析错误是如何从 Q&A(问答)传播到下游的发现任务中的(Fig. 1c)。
1. 正向转化:单项能力支撑项目表现
在许多案例中,模型在特定场景问题上的高分确实能转化为相关项目的成功:
- 一般规律:顶尖模型(如 gpt-5)在分子属性预测、SMILES 字符串操作、基因操控、蛋白质定位以及代数问题上表现出色 。因此,它们在对应的有机分子优化、基因编辑、符号回归和蛋白质设计项目中也表现强劲(Fig. 4a, Supplementary Fig. 2)。
- 晶体结构发现:虽然人们可能质疑 LLM 在生成三维晶体结构方面的能力(因为缺乏内在的 SE(3) 等变架构),但研究发现顶尖的推理模型能生成稳定、独特且新颖的材料,这与它们在 PXRD 晶格预测场景中的熟练度是相符的(Supplementary Table 3)。
- 共同失败:反之亦然,所有模型在量子信息和凝聚态理论问题上的糟糕表现,直接导致了它们在伊辛模型(Ising model)求解项目中的失败。除 deepseek-R1 外,大多数模型甚至无法击败进化算法基准(Supplementary Fig. 19)。
2. 显著的例外 (Striking Exceptions):场景表现无法转化
- 案例一:不懂微观知识,却能搞定宏观优化(TMC 优化项目)
- 现象:没有任何一个模型能熟练回答与过渡金属配合物(TMC)相关的具体问题(例如:预测氧化态、自旋态、氧化还原电位)。
- 反转:尽管如此,gpt-5、deepseek-R1 和 claude-sonnet-4.5 却都能极其高效地在 TMC 优化项目中提出具有高极化率的分子,并在巨大的 137 万个 TMC 搜索空间中成功探索帕累托前沿(Fig. 4b)。
- 启示:这一发现表明,对显式结构-属性关系的严谨知识(rigorous knowledge)并不是 LLM 驱动科学发现的严格前提 。相反,识别优化方向的能力以及促进意外发现(serendipitous exploration)的能力似乎更为关键 。
- 案例二:精通理论题目,却在实战中溃败(逆合成项目)
- 现象:顶尖模型在关于逆合成、反应机理和正向反应预测的“试题”上得分很高 。
- 反转:但在生成有效的多步合成路径的实际项目中,它们却举步维艰。由于在分子或反应的有效性检查中频繁失败,这些模型甚至无法击败传统的逆合成模型基准(Supplementary Table 1)。
- 意外发现:值得注意的是,gpt-4o(一个相对较旧、没有测试时推理的模型)在这个项目中竟然取得了最好的结果,击败了它的继任者(gpt-5-chat)和推理增强版(gpt-5)。
No single model wins on all projects
1. 性能层级的流动性 (No Definitive Hierarchy)
在 SDE 框架涵盖的八个项目中,研究者观察到模型性能并没有一个确定的层级结构 。
- 轮流领跑:领导地位是轮换的,模型在某些项目中表现出色,而在其他项目中则表现不佳 。
- 数据可视化:这一点在 Fig. 4a 中得到了直观展示。该图通过条形图对比了四个模型(gpt-5-chat-latest, gpt-5, deepseek-R1, claude-sonnet-4.5)在八个项目上的归一化性能,可以清晰地看到不同颜色的柱子在不同项目中的高低交替 。
2. 科学发现的复合性质 (Composite Nature of Discovery)
这种性能的变异性反映了科学发现的本质——它是一个整合了多个相互依赖的研究场景的复合过程 。
- 短板效应:因此,要获得出色的项目层级表现,模型至少需要在所有组成场景中都具备熟练度 。任何单一组件的缺陷都会引入复合不确定性,从而拖累整个项目的表现 。
3. 推理增强的局限性 (Absence of Reasoning Benefits)
一个值得注意的发现是,强推理增强(Reasoning enhancements)的预期收益在某些项目中完全缺席 。
- 具体案例:在 逆合成(retrosynthesis) 和 蛋白质设计(protein design) 等项目中,原本预期推理能力至关重要,但实际结果并未显示出推理模型的优势 。这表明需要针对性的后训练(post-training)策略来推动进一步的改进 。
4. 预训练语料优势的减弱 (Less Decisive Pre-training Advantage)
与静态的问题层级评估相比,预训练语料库的优势在发现项目中似乎不那么具有决定性 。
- DeepSeek-R1 的表现:尽管 deepseek-R1 在问题层级基准测试中表现稍弱(可能受限于中文语料为主或训练数据差异),但它在几乎所有推理有利的项目中都排名前二 。这再次印证了 Fig. 4a 中 deepseek-R1(红色柱子)在多个项目中的强劲表现。
5. 距离“超级智能”尚远 (Distant to Scientific “Superintelligence”)
最终结论是,所有当代模型距离真正的科学“超级智能”仍有很大距离 。
- 缺乏全能:目前没有任何一个单一模型能在所有八个(尽管数量有限)不同主题的科学发现项目中表现出色。
- 未来方向:为了有效地编排科学发现的循环,未来的发展应当优先考虑跨多样化场景的均衡知识(balanced knowledge)和学习能力,而不是狭窄的专业化。
Discussion
1. 现有评估范式的失效
作者首先指出,虽然传统基准测试成功追踪了模型在回答通用科学问题上的进展,但结果表明它们是衡量科学发现能力的不充分代理(insufficient proxies) 。
- 核心差距:科学发现依赖于迭代推理、假设生成和证据解释,而不仅仅是静态知识检索 。
- SDE 的价值:SDE 框架通过将孤立问题与模块化研究场景紧密连接,并在项目层级评估模型编排端到端研究的能力,填补了这一空白 。
2. 模型能力的局限与“平台期”
讨论部分再次强调了在 Results 中观察到的几个关键现象的深层含义:
- 高分低能:顶尖模型在去语境化基准(如 GPQA-Diamond)上的高分,并不保证其在 SDE 真实科研场景中的推理能力 。
- 收益递减:曾经在代码和数学领域推动突破的策略——扩大模型规模(Scaling)和增加测试时计算(Test-time compute),在科学发现领域显示出收益递减(diminishing returns) 。
- 趋同的失败:不同提供商的顶尖模型表现出高度的错误相关性,经常在最难的问题上收敛到相同的错误答案 。这暗示了当前的瓶颈可能源于相似的预训练数据分布,而非架构限制 。
3. 项目表现的非线性依赖
作者深入探讨了“做题”与“做项目”之间的复杂关系:
- 知识与探索的权衡:项目层级的表现不仅仅是问答准确率的线性相关 。精确的微观知识(如结构-属性关系)可能不如有效导航假设空间的能力重要 。
- 机缘巧合(Serendipity):模型识别优化方向和促进“意外发现”的能力,可以在一定程度上弥补其在细粒度知识上的缺陷 。
- 能力的不均匀性:LLM 在处理结构化数据(如 TMC 优化)时表现出色,但在需要严格、长程规划和有效性检查的任务(如逆合成)中则非常挣扎 。
4. 未来的发展路径 (Actionable Avenues)
基于上述发现,作者为推动 LLM 在科学发现中的应用提出了四条具体建议:
- 从盲目扩展转向定向训练:应将重点从无差别的规模扩展,转移到针对问题表述(problem formulation)*和*假设生成的定向训练上 。
- 多样化数据源:针对跨模型的高度错误相关性,急需多样化预训练数据源并探索新的归纳偏置(inductive biases),以缓解共同的失败模式 。
- 整合工具使用 (Tool Use):许多高难度场景需要语言推理与领域模拟器、结构构建器的紧密耦合。因此,训练和评估必须超越文本准确性,优先考虑可执行的操作(executable actions),特别是调用工具、调试执行失败以及根据反馈迭代协议的能力 。
- 针对科学推理的强化学习:鉴于针对代码和数学优化的推理增强在科学发现项目中收益甚微,开发专门针对科学推理的强化学习策略是一个充满希望的前沿方向 。
5. 局限性与展望
- 偏差:基准反映了贡献专家的特定研究兴趣和方法论偏好,目前尚缺乏地球科学、社会科学等领域的覆盖 。
- 可复现性:依赖商业 API 带来了性能波动问题,未来应更多采用本地部署的开源模型作为基准 。
- 安全性:必须警惕日益强大的生物 AI 系统带来的安全风险(如生物安全),包括越狱和滥用路径 。
尽管存在这些限制,SDE 提供了第一个跨越科学发现全流程的综合评估,为社区构建更复杂、更现实的评估奠定了坚实基础 。
Methods
Research scenario and question collection
SDE 的构建并非简单的题目堆砌,而是通过生物、化学、材料和物理四个领域的结构化协作完成的。
1. 核心架构:从项目到场景 (From Project to Scenario)
正如 Fig. 1c 所示,数据收集遵循“领域 (Domain) $\rightarrow$ 项目 (Project) $\rightarrow$ 场景 (Scenario) $\rightarrow$ 问题 (Question)”的层级结构:
- 定义场景 (Defining Scenarios):
- 来源:每个领域的专家小组首先确定那些在真实科学发现工作流中反复出现、且具有基础推理模式的研究场景。
- 标准:这些场景取材于正在进行或过去的研究项目,反映了活跃的科学兴趣,而非教科书式的练习。
- 模块化:一个“场景”被定义为一个模块化的、独立的科学推理单元(例如化学中的“正向反应预测”),它是解决更宏大研究项目的构建模块。
2. 问题生成策略:混合模式 (Hybrid Generation Strategy)
一旦确定了关键场景,专家们采用了半自动生成与人工手动策展相结合的混合策略来构建具体问题:
- 半自动生成 (Semi-automated):
- 对于有结构化数据可用的场景,通过从现有基准数据集(如 GPQA)或开放数据集(如 NIST)采样,利用模板脚本将结构化条目转换为自然语言问答对。
- 利用领域特定的计算流程(如 RDKit)来获取参考答案(例如计算分子描述符)。
- 人工手动起草 (Manual Curation):
- 对于缺乏公开结构化记录的场景(特别是实验技术相关的场景),问题由领域专家使用统一模板手动编写,以确保与半自动生成问题的一致性。
3. 质量控制与验证 (Quality Control)
为了保证基准的权威性,每个环节都设有严格的审核机制:
- 专家评审:每一个问题都经过了小组评审,只有在对问题的有效性(validity)和正确性(correctness)达成共识后,该问题才会被纳入。
- 数量控制:为了减少随机方差,每个场景至少包含 5 个经过验证的问题。
- 格式规范:问题格式包括多项选择和简答题。为了避免评分歧义,采用了精确匹配(exact-match)、基于阈值的容差(针对数值)或相似度评分(针对分子结构)等评估方式。
4. 数据集统计 (Dataset Statistics)
最终生成的 SDE 数据集规模庞大且覆盖面广,共包含 43 个不同的研究场景和 1,125 个问题:
- 化学 (276题):涵盖正向反应预测、逆合成、分子属性估算、NMR 结构解析、实验技术等。
- 材料 (486题):涵盖腐蚀预测、材料安全、PXRD 晶系与晶格预测、MOF 合成与稳定性等。
- 生物 (200题):涵盖酶反应预测、蛋白质定位、GWAS 致病基因识别、CRISPR 递送策略等。
- 物理 (163题):涵盖天体物理与宇宙学、量子信息科学、凝聚态物理、计算物理等。
Research project collection
1. 项目架构与核心逻辑
- 多场景整合:研究团队策划了 8 个 跨越生物、化学、材料和物理的研究项目 。每个项目都不是孤立的任务,而是涉及多个模块化的研究场景。例如,一个“逆合成路径设计”项目自然会涉及单步逆合成、反应机理分析和正向反应预测等多个场景 。
- 问题公式化:每个研究项目都被制定为一个搜索或优化问题(search or optimization problem) 。
- 假设空间:LLM 在假设空间(如所有可能的分子结构、符号方程的空间)中提出建议(Hypothesis) 。
- Oracle 验证:这些假设由计算 Oracle(如模拟器)检查以评估适应度(Fitness) 。
- 闭环反馈:评估结果被反馈给 LLM 以改进其提案,形成 Fig. 4a 所示的科学发现循环 。
2. 统一的优化工作流 (Evolutionary Optimization)
为了标准化评估,作者选择了进化优化(Evolutionary Optimization)作为简单高效的搜索方法,具体包含三个步骤 :
- 初始化 (Initialization):从 LLM 冷启动生成或从预定义集合热启动,形成初始假设集。
- 突变、交叉与从头提议 (Mutation, Crossover, and De novo):LLM 根据从池中采样的父代假设生成后代。
- 选择 (Selection):生成后代后,根据适应度保留父代和后代中排名靠前的假设。 这一过程重复进行,直到收敛或达到最大 Oracle 调用次数 。
3. 八大具体研究项目详解
化学领域 (Chemistry)
- 逆合成路径设计 (Retrosynthesis pathway design):
- 目标:规划反应路径,将目标分子分解为市售前体(Building blocks) 。
- 约束:每一步分解必须遵守可用的反应模板,定义为一个规划问题(Planning problem) 。
- 数据:基于 USPTO 反应数据和 Chen et al. 的工作 。
- 分子优化 (Molecule optimization):
- 目标:在巨大的化学空间中搜索具有最佳属性(如药物发现所需的属性)的分子结构 。
材料领域 (Materials)
- 过渡金属配合物优化 (TMC optimization):
- 挑战:配体选择带来的组合爆炸。
- 任务:在进化循环下,推动 LLM 生成具有目标 HOMO-LUMO 能隙和极化率(polarisability)的候选 TMC,这需要深刻理解过渡金属化学。
- 晶体结构发现 (Crystal structure discovery):
- 挑战:候选结构必须同时满足三维周期性、化学有效的原子配位、电荷中性和热力学稳定性等多重物理约束。
- 任务:利用 LLM 对参考父结构进行隐式交叉和突变,生成具有低形成能(energy above the hull)的新型晶体结构。
生物领域 (Biology)
- 蛋白质序列优化 (Protein sequence optimization):
- 空间:包含 4-250 个突变位点的蛋白质序列,每个位点有 20 种氨基酸选择。
- 任务:LLM 被用来优化蛋白质序列以达到最佳适应度(Fitness),目标函数由 Oracle 定义。
- 基因编辑 (Gene editing):
- 目标:在众多可能的基因中找到子集,使其在受到干扰(perturbation)时产生特定的表型。
- 任务:LLM 被迫计新的实验来提出干扰建议,以发现新表型。
物理领域 (Physics)
- 符号回归 (Symbolic regression):
- 挑战:发现支配科学观测的数学模型是一个重大挑战。
- 任务:LLM 需要找到能够恢复实验观测结果的符号方程(symbolic equations),通过模拟观测的误差来衡量优劣。
- 求解伊辛模型 (Solving Ising model):
- 挑战:组合配置空间呈指数级增长。
- 任务:LLM 模仿人类科学家的发现过程,推断出使伊辛模型哈密顿量(Hamiltonian)最小化的最佳自旋配置。
Model evaluation
1. 问题层级评估 (Question-level)
这一层级主要评估模型在 43 个具体研究场景中的答题准确率。
- 评估框架:所有评估均使用
lm-evaluation-harness的定制分支进行。每个场景都由一个 YAML 配置文件指定,该文件加载相应的 Hugging Face 数据集。 - 解码设置:为了保证结果的可复现性,默认采用确定性解码(Deterministic decoding),设置
temperature = 0且do_sample = false。- 例外:部分模型有明确的参数要求,例如
gpt-5仅接受temperature = 1。
- 例外:部分模型有明确的参数要求,例如
- 提示与格式:跨领域的绝大多数场景都使用了标准化的提示词(Prompt)和输出格式,要求 LLM 将最终答案包含在 XML 风格的标签中(例如:
<answer>...</answer>)。通过正则表达式提取标签内容后,通常进行不区分大小写和标点符号的精确匹配(exact-match)评分。 - 领域特定的评分机制:为了适应不同科学领域的特殊需求,评估引入了专门的工具:
- 化学:对于分子结构输出(如光谱结构解析),使用 RDKit 进行规范化,并计算 Tanimoto 相似度进行评分;对于数值预测(如氧化还原电位),则检查预测值是否落在定义的容差窗口(tolerance window)内。
- 材料:晶格参数回归任务允许在 3 $\mathring{A}$ 的误差范围内获得部分分数。
- 生物:对于结构化描述符(如 LogP、分子量)采用带容差的精确匹配,CRISPR 递送预测采用加权部分评分。
- 物理:对于代数回答,使用符号验证器(
math-verify包)来解析,只要数学表达式等价即可得分。
- 分数聚合:所有指标均归一化为 [0, 1] 区间 11。首先计算每个场景的平均分,然后将同一领域下所有主题的得分取算术平均,得出该领域的最终得分。
2. 项目层级评估 (Project-level)
这一层级评估模型在完整的科学发现循环(假设-实验-观测)中的表现。
- 评估框架:使用专门开发的
sde-harness框架执行。 - 评分方法:将每个项目的表现聚合为一个单一的分数。具体做法是先对每个子目标(sub-objectives)的得分进行归一化,然后取平均值作为该项目的最终得分。
- 图表引用:这一聚合评分的展示方式在 Fig. 4a 中有直观体现,该图通过条形图展示了各模型在归一化单一指标上的表现。
- 评估模型限制:由于运行完整项目的成本远高于单题评估,项目层级评估仅针对部分顶尖模型进行,包括 gpt-5-chat-latest, gpt-5, claude-sonnet-4.5 和 deepseek-R1,涵盖了最佳的非推理模型和推理模型。