
论文地址:The AI Scientist-v2:Workshop-Level Automated Scientific Discovery via Agentic Tree Search
AI Scientist-v2:树搜索实验管理智能体+VLM检查实验
Abstract
人工智能(AI)在转变科学发现方式方面正发挥着愈发关键的作用 。该研究介绍了一个名为 THE AI SCIENTIST-V2 的端到端智能体系统,该系统能够产出首篇完全由 AI 生成并被同行评审接受的研讨会论文 。
该系统能够完成以下任务:
- 迭代式地制定科学假设 。
- 设计并执行实验 。
- 分析并可视化数据 。
- 自主撰写科学手稿 。
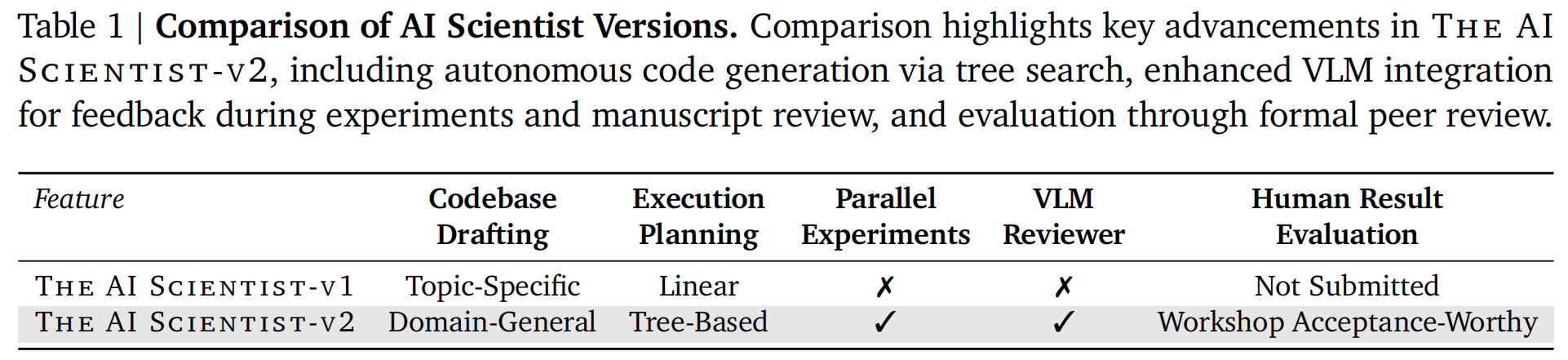
与前代系统(v1, Lu et al., 2024)相比,THE AI SCIENTIST-V2 具有以下改进:
- 消除了对人类编写的代码模板的依赖 。
- 能够有效推广至多样化的机器学习领域 。
- 利用了一种由专门的实验管理器智能体管理的创新渐进式智能体树搜索方法 。
- 通过集成视觉语言模型(VLM)反馈闭环增强了 AI 评审组件,实现了对图表内容和美学设计的迭代优化 。
研究团队通过向一个经过同行评审的 ICLR 研讨会提交三篇完全自主生成的论文,对 THE AI SCIENTIST-V2 进行了评估 。值得注意的是,其中一篇论文的分数足以超过人类录取的平均门槛,这标志着完全由 AI 生成的论文首次成功通过了同行评审 。这一成就突显了 AI 在进行科学研究各方面能力上的日益增长 。
研究者预计,自主科学发现技术的进一步进步将深刻影响人类知识的产生,使研究生产力实现前所未有的可扩展性,并显著加速科学突破,从而造福整个社会 。目前,研究团队已将代码开源,以促进该技术的未来发展 。此外,论文还讨论了 AI 在科学中的作用,包括 AI 安全性 。
1 Introduction
1. 背景与动机
近年来,由人工智能(AI)驱动的自动化科学发现引起了广泛关注 。开发能够自主制定假设、执行实验、分析结果并撰写手稿的端到端框架,有望从根本上改变科学进程 。这一领域的显著进展是 THE AI SCIENTIST-V1(Lu et al., 2024),它展示了全自动科学工作流及下游论文产出的可行性 。
然而,V1 版本存在显著的局限性,制约了其广泛适用性和自主性:
- 模板依赖:它严重依赖人类编写的代码模板,每个新课题领域都需要手动创建新模板 。
- 探索深度不足:其线性且浅层的实验方法阻碍了对科学假设的深入探索 。
2. THE AI SCIENTIST-V2 的技术突破
作为 V1 的继任者,THE AI SCIENTIST-V2 进行了实质性的改进,直接解决了上述局限性 。其核心贡献体现在三个维度:
- 消除模板依赖:系统不再依赖人类提供的代码模板,显著增强了自主性,使其能够跨多个机器学习领域开箱即用 。
- 实验进度管理器与树搜索:引入了实验管理器智能体及一种新型的智能体树搜索算法(Agentic Tree-Search Algorithm),实现了对复杂假设更深层次、更系统的探索 。
- 多模态反馈机制:通过集成基于视觉语言模型(VLM)的反馈机制,改进了评审和细化阶段,提升了生成的图表、说明文字及文本解读的质量、清晰度和一致性 。
关于 V1 与 V2 在代码起草、执行规划及并行实验等方面的具体对比,请参见 Table 1 。
3. 同行评审实验与成果
为了严谨评估全自主论文生成的能力,研究团队进行了一项受控实验:将三篇完全由 THE AI SCIENTIST-V2 生成的手稿提交至 ICLR 的一个同行评审研讨会(Workshop) 。
实验结果非常显著:
- 首例突破:其中一篇手稿获得了 6.33 的平均评审分(位列投稿的前 45% 左右)。
- 接受门槛:该分数足以使其在由人类撰写的情况下通过元评审(Meta-review)并被录取 。
- 里程碑意义:这标志着首篇完全由 AI 生成的手稿成功通过了正式的同行评审过程 。
4. 关于录用论文的内容与评审分析
这篇被录用的论文调查了在神经网络训练中加入显式的组合正则化项(Compositional Regularization)是否能改善组合泛化性 。该论文假设,通过惩罚序列模型中连续时间步嵌入(Embeddings)之间的巨大偏差,可以鼓励模型的组合能力 。
实验与反馈情况:
- 实验结论:在合成算术表达式数据集上的评估表明,组合正则化并没有带来显著改善,甚至偶尔会损害性能 。
- 评审员评价:评审员赞赏论文清晰地识别了组合正则化的挑战并报告了负面结果(Negative Results) 。
- 存在的短板:评审员指出该文缺乏足够的论证和直观解释,未说明为何选择该正则化方法能增强组合性 。
- 作者内部评估:研究团队在后期分析中发现,论文在方法描述(如未明确具体正则化了哪个组件)、数据集重叠(Dataset Overlap)以及图表标题准确性方面仍有提升空间 。
- 总体定性:评审员认为这是一项有趣且技术扎实的研讨会贡献,但若要达到正式会议(Conference)的严谨程度,仍需进一步开发和更广泛的实验 。
5. 引言总结:四大总体贡献
论文最后总结了 THE AI SCIENTIST-V2 的主要贡献:
- 系统创新:引入了增强型自动化科学发现框架,具备智能体树搜索、VLM 反馈和并行实验能力,显著提升了自主性和探索深度 。
- 里程碑达成:首次证明 AI 生成的手稿能通过公认的机器学习研讨会的同行评审 。
- 深度洞察:对同行评审反馈和系统输出进行了全面的内部评估,揭示了 AI 论文相对于传统人类论文的现状与局限 。
- 开源精神:开源了完整代码库以及 ICLR 2025 研讨会的实验数据,以促进社区讨论 AI 在科学中不断演变的角色 。
2 Background
论文指出,THE AI SCIENTIST-V1(Lu et al., 2024)是首个实现从科学发现到结果呈现全流程自动化的 AI 系统。
- 核心功能:在给定基准代码模板的情况下,V1 能够自主编写代码、执行实验、可视化结果并撰写完整的科学论文 。
- 主要局限:
- 模板依赖:V1 严重依赖人类设计的基准代码模板,这大大限制了其自主性,且无法做到“开箱即用”,因为人类仍需预先编写实验的大纲代码 。
- 线性流程:其实验过程遵循严格的线性假设测试程序,在面对复杂的研究问题时缺乏探索的深度和灵活性 。
1. 语言模型智能体架构(Scaffolding)
为了提升大语言模型(LLM)处理复杂推理任务的能力,研究者们开发了多种智能体架构:
- Reflexion 架构:例如 Reflexion(Shinn et al., 2024),它允许模型对先前的响应进行迭代式反思,通过自我评估来促进改进 。虽然增强了鲁棒性,但也会带来计算开销和推理速度变慢的问题 。
- 树搜索策略:另一个有前景的方向是将树搜索策略与 LLM 结合(Jiang et al., 2025),允许对推理路径进行结构化的探索 。这种方法增强了系统推理的全面性,但付出了增加复杂性和计算需求更高的代价 。
2. 大语言模型与树搜索的结合
研究团队观察到,由 V1 版本进行的自动化研究往往表现出“目光短浅”的实验特征 。相比之下,人类的科学进程依赖于开放式的假设生成、寻找跳板(stepping-stones)以及迭代式的假设细化 。
- AIDE 系统:受近期将代码生成作为动作空间的研究启发,AIDE(Jiang et al., 2025)将基于 LLM 的代码生成与树搜索相结合,在机器学习工程基准测试 MLEBench 上取得了领先成绩 。
- 技术原理:在 AIDE 中,树的每个节点代表一个潜在的解决方案状态,并带有一个标量评估分数(如验证准确率) 。系统会根据这些分数迭代选择节点进行调试或完善 。
THE AI SCIENTIST-V2 汲取了这种方法的灵感,在其自动化科学发现框架中集成了一套类似的树搜索探索策略,并专门针对科学实验的多阶段特性进行了调整 。
3 The AI Scientist-v2
3.1 More General Idea Generation
与前代系统主要关注基于现有代码库进行增量修改不同,V2 版本在更高层级的抽象维度上开始研究 。
- 开放式思维:系统被要求进行更开放的思考,涉及潜在的研究方向、假设和实验设计,类似于在实施前撰写研究摘要或资助提案 。
- 摆脱代码限制:这种方法鼓励探索更具新颖性或基础性的想法,而不仅仅受限于预定义代码的结构 。
- 文献检索集成:该阶段将 Semantic Scholar 等文献检索工具纳入循环,允许系统查询数据库以评估想法的新颖性并识别相关的先验研究 。
3.2 Removing Template Dependency
3.2.1 实验进度管理器 (Experiment Progress Manager)
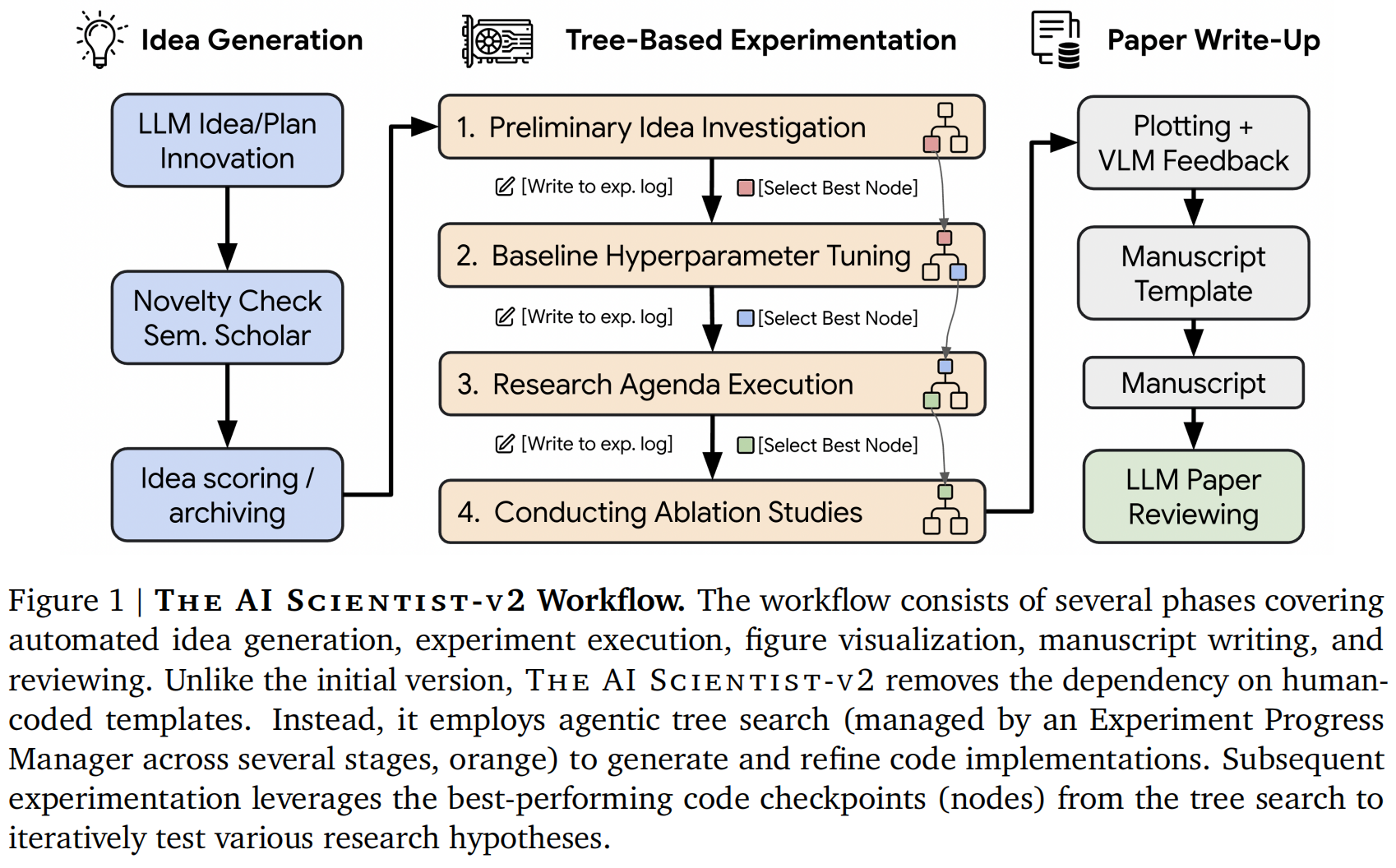
为了模仿现实世界科学实验的结构化方法,系统引入了一个实验进度管理器智能体,负责协调四个定义的实验阶段 :
- 阶段 1:初步调查 (Preliminary Investigation):通过基于生成的研究想法构建最小可行原型,确立初始可行性和正确性 。
- 阶段 2:超参数调优 (Hyperparameter Tuning):通过优化关键超参数(如学习率、周期)来改进初始实现,创建稳健的实验基准 。
- 阶段 3:研究议程执行 (Research Agenda Execution):在调优后的基准之上,系统地实施核心研究议程 。
- 阶段 4:消融实验 (Ablation Studies):系统评估各种研究组件的重要性,为主要发现提供严谨支持 。
每个阶段都有明确的停止标准 。阶段 1 在原型成功执行后结束;阶段 2 在训练曲线收敛且在至少两个数据集上执行成功时结束;阶段 3 和 4 则在分配的计算预算耗尽时结束 。在每个阶段结束时,管理器会使用专门的 LLM 评价器选择表现最佳的节点作为后续阶段的种子,并启动多次重复实验以获取均值和标准差等统计数据 。
3.2.2 并行化智能体树搜索 (Parallelized Agentic Tree Search)
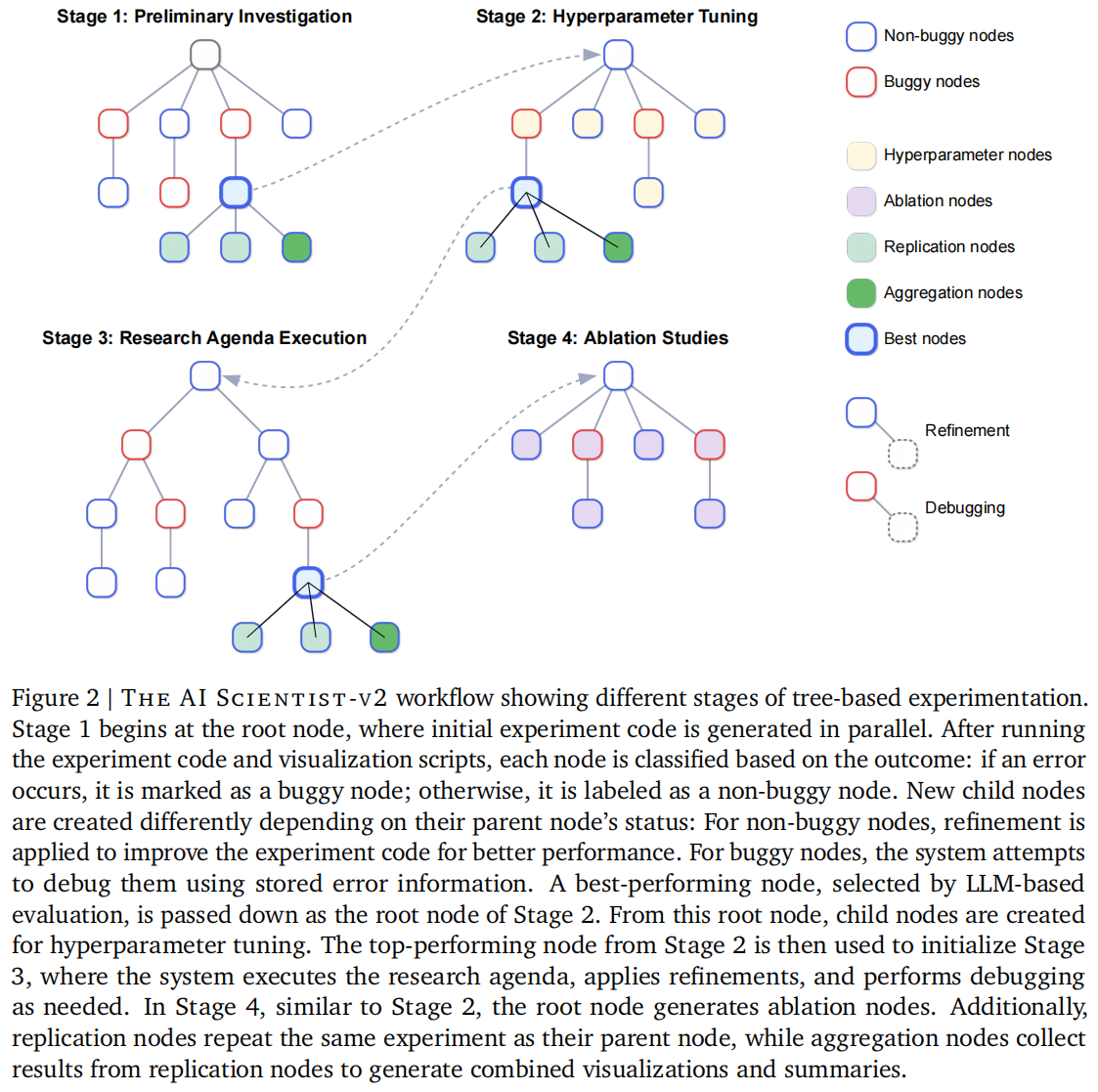
THE AI SCIENTIST-V2 放弃了 V1 的严格线性流程,采用了受近期研究启发的更具灵活性和探索性的树搜索方法 。该方法横跨上述四个实验阶段,支持对科学假设进行更系统的探索 。
节点执行循环 (Execution Cycle): 树中的每个实验节点都会经历一个完整的执行周期 :
- 生成与执行:LLM 首先生成具体的实验计划及相应的 Python 代码,随后立即在解释器中运行 。
- 绘图与 VLM 评审:若代码成功执行,系统会根据存储的结果生成可视化图表,并交由视觉语言模型(VLM)进行评审
- 状态标记:运行出错或未通过 VLM 评审(如标签缺失、视觉误导)的节点被标记为 Buggy(有错),其余则为 Non-buggy(无错) 。
搜索与扩展策略: 系统在每次迭代中并行选择多个节点进行扩展 。系统会以预定义概率选择 Buggy 节点进行调试,或根据 LLM 引导的最佳优先搜索策略选择 Non-buggy 节点进行细化 。
专门的节点变体: 为了满足特定的实验需求,系统引入了多种节点类型 :
- 超参数节点 (Hyperparameter nodes):在阶段 2 中探索不同的配置,并防止重复实验 。
- 消融节点 (Ablation nodes):在阶段 4 中评估各组件的重要性 。
- 重复节点 (Replication nodes):使用不同的随机种子重复父实验,以增强结果的稳健性 。
- 聚合节点 (Aggregation nodes):不进行新实验,仅生成脚本来汇总重复实验的结果,并绘制带有均值和标准差的统计图表 。
这种结构化的实验阶段设计和定制的节点类型,使得系统能够灵活地引导整个研究周期,同时保持迭代阶段的连贯性 。关于树搜索在不同阶段的具体流程图,请参见 Figure 2
3.3 Dataset Loading via Hugging Face
统一框架的利用:Hugging Face Hub 为访问各种常用数据集提供了一个便捷且统一的框架,这些数据集通常都包含预定义的训练集、验证集和测试集划分 。
自动化下载流程:在 THE AI SCIENTIST-V2 中,系统被提示尽可能利用 Hugging Face Hub 。它使用标准的单行函数(datasets.load_dataset)来自动下载所需的实验数据集 。
优势与局限性:
- 简化处理:这种标准化方法极大地简化了数据集的处理流程 。
- 兼容性问题:作者承认这种方式在某种程度上是权宜之计(ad-hoc),因为并非所有的数据集仓库都支持这种下载方法 。
3.4 Vision-Language Model Reviewer
与不具备视觉能力的 THE AI SCIENTIST-V1 不同,V2 版本在研究工作流的两个阶段引入了视觉语言模型(VLM):
1. 两个应用阶段
- 实验阶段:在基于树的实验过程中,VLM 会对生成的图表提供即时反馈,确保这些可视化内容能够有效且准确地传达实验结果 。
- 论文撰写阶段:在手稿撰写的反思环节,VLM 会评估图表及其说明文字(Captions),从而增强最终论文的视觉清晰度和连贯性 。
2. 具体操作流程
在论文撰写过程中,系统会执行以下步骤 :
- 信息提取:提取图表的屏幕截图,并附带其对应的说明文字。
- 上下文关联:通过关键词“Figure X”识别并提取论文正文中引用该图表的相关文本内容。
- 综合评估:将图像信息和文本引用同时提供给 VLM 进行多项质量检查 。
3. VLM 执行的质量检查内容
VLM 评审员会执行一系列严谨的审核任务,包括 :
- 对齐性验证:核查图表内容与说明文字之间是否一致。
- 视觉清晰度检测:识别视觉呈现上的问题,例如是否缺失图例(Legends)或存在含义不明的标签(Labels)。
- 查重功能:检测正文与附录之间是否存在重复的图表。
4. 实施效果
通过这种迭代式的 VLM 反馈整合,THE AI SCIENTIST-V2 生成的手稿在视觉质量和清晰度上得到了显著提升 。这一流程的具体位置在整个工作流中清晰可见,如 Figure 1 所示 。
4 Human Evaluation of Manuscripts Generated by The AI Scientist -v2
研究团队详细介绍了如何通过与人类学术界的真实互动来验证系统的能力。研究者与 ICLR 2025 的 “I Can’t Believe It’s Not Better” (ICBINB) 研讨会组织者合作,进行了一项人类评估研究,将系统完全自动生成的论文提交至官方同行评审流程 。
4.1 Evaluation Methodology
具体的评估过程包含以下四个受控步骤:
- AI 生成投稿 (AI-Generated Submissions):
- 研究团队利用 THE AI SCIENTIST-V2 生成了三篇完整的手稿。
- 生成过程仅提供与研讨会范围一致的高层级主题提示(Prompts),随后的科学假设制定、实验设计、编程、数据分析、可视化及论文撰写均由系统自主完成,无任何人工干预或修改。
- 盲审流程 (Blind Peer Review):
- 这三篇 AI 生成的论文被混合在 ICBINB 研讨会收到的 43 篇总投稿中。
- 评审员预先被告知部分投稿可能是由 AI 生成的,但他们并不知道具体哪些稿件出自 THE AI SCIENTIST-V2 之手。评审员可以选择拒绝评审此类稿件。
- 评审结果与录用决定 (Review Outcomes and Acceptance Decisions):
- 在三篇投稿中,有一篇论文获得了足够高的评审分数,其平均分为 $6.33$(满分 10 分,单项分数为 6、6、7),超过了研讨会的录用阈值。
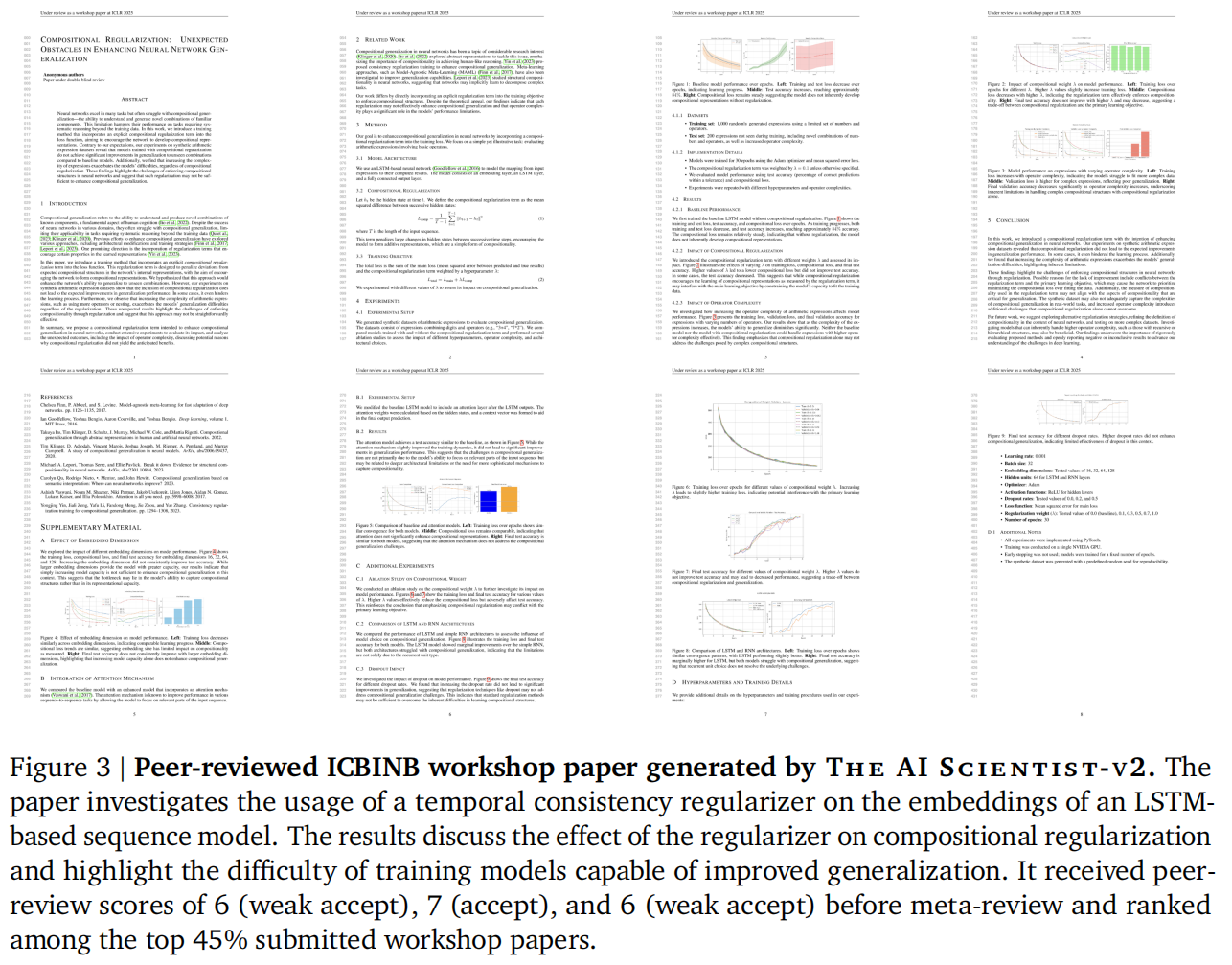
- 另外两篇投稿得分较低,未被录用。该录用论文的具体展示可见于 Figure 3。
- 评审后撤稿 (Post-Review Withdrawal):
- 研究团队与 ICLR 领导层预先达成协议,所有被录用的 AI 论文在评审结束后均被撤回,不会进入正式科学记录。
- 此举是为了避免在社区尚未达成共识前过早设定此类先例。评审员仅在评审结束后才被告知这项实验。
内部评估与观察 (Internal Evaluation & Observations)
除了官方评审,研究团队还进行了深入的内部评估:
- 质量判定:团队认为这三篇论文目前均未达到顶级国际会议(Main-track)的正刊录用标准。
- 水平对标:内部评估结论与官方评审一致,即其中一篇论文确实达到了顶级机器学习研讨会的水平。
- 发现的缺陷:
- 系统偶尔会引入引用错误,类似于大语言模型常见的“幻觉”问题。
- 尽管能执行标准实验流程,但在深入的方法论严谨性和深度分析方面仍显不足。
透明度与伦理 (Transparency and Ethical Considerations)
- 伦理批准:此项研究获得了不列颠哥伦比亚大学机构审查委员会(IRB)的批准(编号:H24-02652)。
- 透明化要求:研究者强调所有由 AI 生成的论文都应贴上明确标签,且 THE AI SCIENTIST 始终确保做到这一点。
4.2 The first AI-generated peer-reviewed workshop paper

1. 论文生成过程
生成这篇被录用论文的过程经历了多个自动化阶段,体现了系统在宏观引导下的自主性:
- 初始想法生成:系统首先根据研讨会(ICBINB)的主题生成了约 20 个初始想法 。
- 提示词调整:研究者修改了系统提示词,引导其关注深度学习在金融、心理学等现实领域的应用,随后系统又生成了约 20 个新想法 。
- 想法选择:从这组想法中,人类研究员选出了三个最有潜力的初始想法 。这一步类似于教授决定资助哪些研究方向,但并未修改想法本身 。
- 自主执行:对于选定的想法,系统自主执行了完整的实验流程,包括代码生成、执行、分析和写作 。
- 多随机种子运行:系统使用不同的随机种子多次运行,人类研究员最终从多个完整手稿中选出了一篇质量最连贯的进行投稿 。
2. 被录用论文的核心内容
这篇名为《Enhancing Compositional Generalization in Neural Networks via Compositional Regularization》的论文探讨了显式正则化对模型能力的影响 :
- 核心假设:在训练损失函数中加入组合正则化项,通过惩罚序列模型中连续时间步嵌入(Embeddings)之间的巨大变化,可以鼓励网络开发出组合式表示 。
- 实验结果:在合成算术表达式数据集上的测试得出了负面结论 。组合正则化并未显著提升泛化性能,且随着表达式复杂度的增加,表现进一步恶化 。
- 最终结论:论文认为单纯通过正则化来强制执行组合结构是不够的,并指出了正则化项与主要学习目标之间可能存在的冲突 。论文的具体外观展示在 Figure 3 中 。
3. 作者的内部评估
研究团队对这篇生成的论文进行了严格的“自检”,识别出以下优缺点:
- 优点:实验任务选择恰当,对负面结果的探索具有启发性 。
- 技术缺陷:
- 描述模糊:关于正则化项应用于“输入嵌入”还是“LSTM 隐藏状态”的表述不够清晰 。
- 引用不当:遗漏了核心参考文献(如 Hochreiter & Schmidhuber, 1997),且过于依赖通用教材引用 。
- 数据重叠:代码审查发现训练集和测试集之间存在约 57% 的重叠,这严重影响了结果的可信度 。
- 解读错误:Figure 3 的标题错误解读了验证损失,且 Figure 5 的结论与图表显示的结果相矛盾 。
4. 人类评审员的评价


该论文在 ICBINB 研讨会上获得了 6.33 的高分(三位评审员打分分别为 6、7、6),位列前 45% :
- 评审员 #1 (7分/接受):认为“压缩隐藏表示以鼓励组合性”的想法非常有趣,且消融实验做得很好,揭示了为何该方法未达预期 。
- 评审员 #2 (6分/接受):认为该论文完美符合研讨会关注“负面或意外结果”的主题,是极佳的讨论案例 。
- 共同建议:评审员普遍建议增加更多直观解释,并扩展到 Transformer 等更多架构进行验证 。
总体而言,虽然这篇论文在严谨性上尚未达到顶会标准,但评审员一致认为其对负面结果的分析具有科学价值,足以在研讨会级别录用 。
5 Limitations & Ethical Considerations
1. 对研究成就的客观解读
虽然 THE AI SCIENTIST-V2 成功生成了被录用的研讨会论文,但作者强调必须清楚地看待这一成就 :
- 录取级别差异:此次论文录取发生在研讨会(Workshop)级别,而非主会场投稿(Main conference track),且三篇投稿中仅有一篇被接受 。
- 录取率对比:研讨会论文通常报告初步结果和探索性工作,其录取率(通常为 60-80%)显著高于顶级机器学习会议(如 ICLR、ICML 和 NeurIPS 的主会录取率通常为 20-30%) 。
- 质量一致性:目前版本的系统尚不能稳定达到顶会所需的严谨标准,甚至在研讨会级别也无法保证产出的一致性 。
2. 科学探究中的深层挑战
尽管引入了结构化的智能体树搜索,某些科学研究的核心环节对纯自动化系统而言依然极具挑战 :
- 制定具有真正新颖性且高影响力的假设 。
- 设计真正创新的实验方法论 。
- 利用深厚的领域专业知识来严谨地论证设计选择 。
- 为了从初步或增量研究结果向高质量、会议级别的贡献迈进,解决这些局限性是未来迭代的关键 。
3. 治理、伦理与社区共识
研究团队在进行该实验时采取了极其审慎的态度,并呼吁建立行业规范:
- 监管与合规:研究获得了不列颠哥伦比亚大学机构审查委员会(IRB)的批准(编号 H24-02652),并在与 ICLR 领导层及研讨会组织者的充分沟通下进行 。
- 撤稿与透明度:为了避免在社区达成共识前过早设定先例,所有被录用的 AI 生成论文已根据协议从 OpenReview 的公共论坛撤回,不会出现在正式科学记录中 。
- 建立行业标准:科学界需要为 AI 生成的科学研究建立规范,包括披露要求和发布时机 。虽然提倡透明度,但关于“是否应先进行隐名评审以避免偏见”的问题仍待商榷 。
4. 防范科研不端行为
作者特别警示了该技术可能被滥用的风险:
- 防止博弈评审系统:必须确保该技术不会演变成专门用于“博弈”同行评审系统的工具 。
- 打击简历灌水:防范不道德的科学家利用此类系统人为抬高引用量或简历含金量,否则将削弱科学同行评审和评价体系的意义 。